9.1合并算法整体说明
合并算法作为合并APP中最核心的计算框架,涵盖在合并场景中的各种需要执行的业务场景,包括但不限于重分类、折算、权益法调整、未实现利润处理、各种抵消等主表、附表及管报所需要的业务数据处理逻辑。
1. 定位
在合并APP中,所有的计算场景不外乎两类,一类是散落在接口、表单等各业务环节中,可单独执行的局部逻辑,比如:一张报表的重分类,一张附表的折算等。另一类,则是绑定在合并流程控制组件中,作为一个整体来执行的合并规则。
本部分主要讲解挂载在【合并流程控制组件】中整体调度的计算规则。
方案实施建议:
1、有必要绑定在合并流程组件中整体运行的脚本:合并校验、抵销、汇总
2、可拆开单独绑定在报表,也可整体运行的脚本:年初结转、主附表间计算、科目重分类
3、建议绑定在接口的脚本:基于原始采集数据的重分类,比如客商净额重分类等
其中,第二项考量的主要因素是计算量的大小,客户对于执行一次大合并所耗费时间的看重程度,放在整体脚本中运行的好处是用户不会漏算,挂载在单独报表上运行的好处是节省整体合并时间(但需要打开报表执行计算,因此一般叠加校验逻辑,防止数据变更而未计算)
2. 基本概念
2.1 合并算法组成部分
一套合并算法包括以下三部分:
-
配置信息 -
执行框架/合并调度 -
自定义脚本
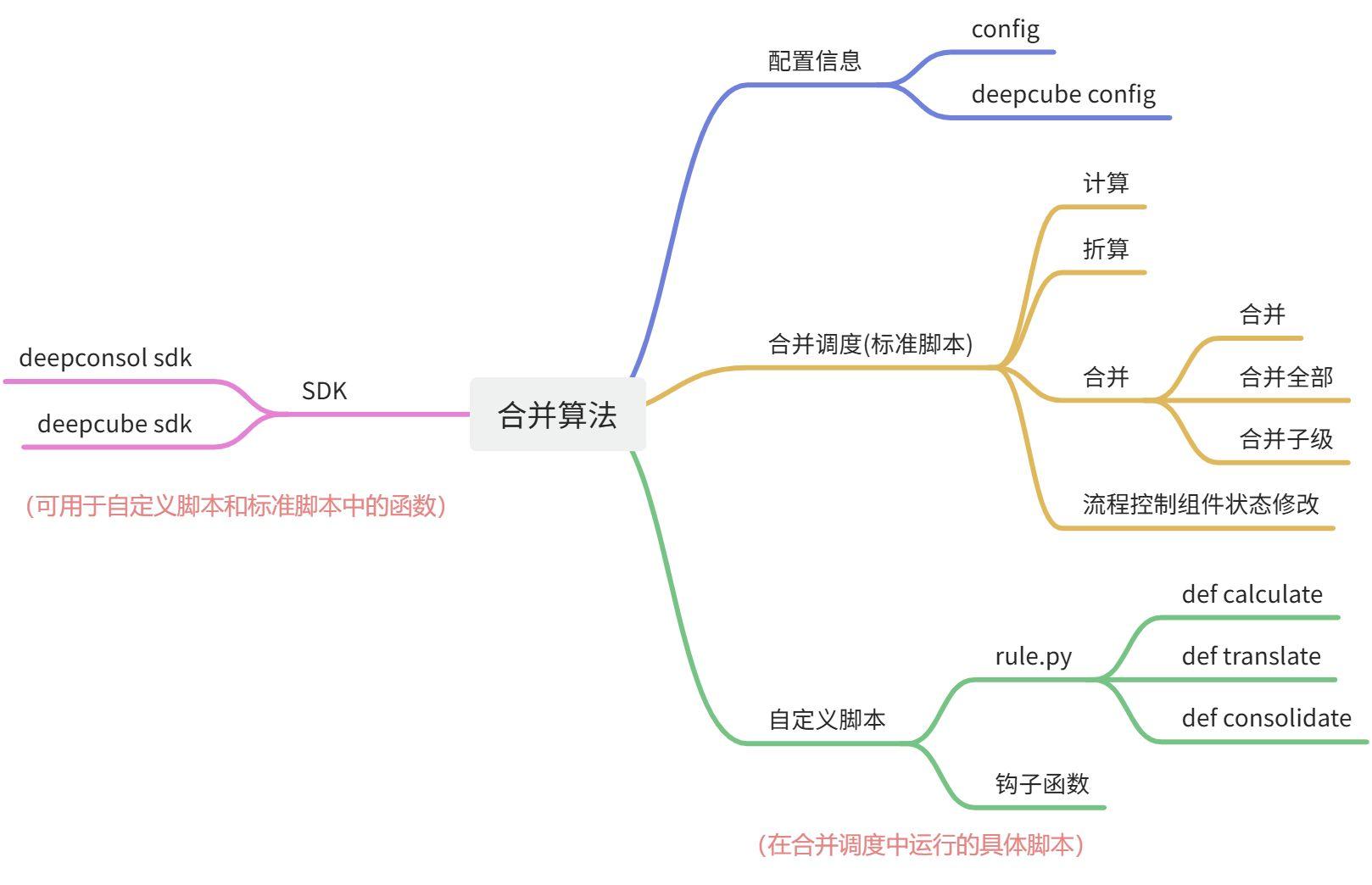
注:除deepcube sdk 注册到Python服务由系统提供之外,其他(包含deepconsol sdk、config、deepcube_config、合并调度算法、自定义脚本等)均以Python文件包的形式提供。
2.2 合并调度与合并流程组件的关系
合并流程控制组件提供合并动作执行、审批节点流转等业务逻辑,但是具体的调度逻辑由合并算法提供:
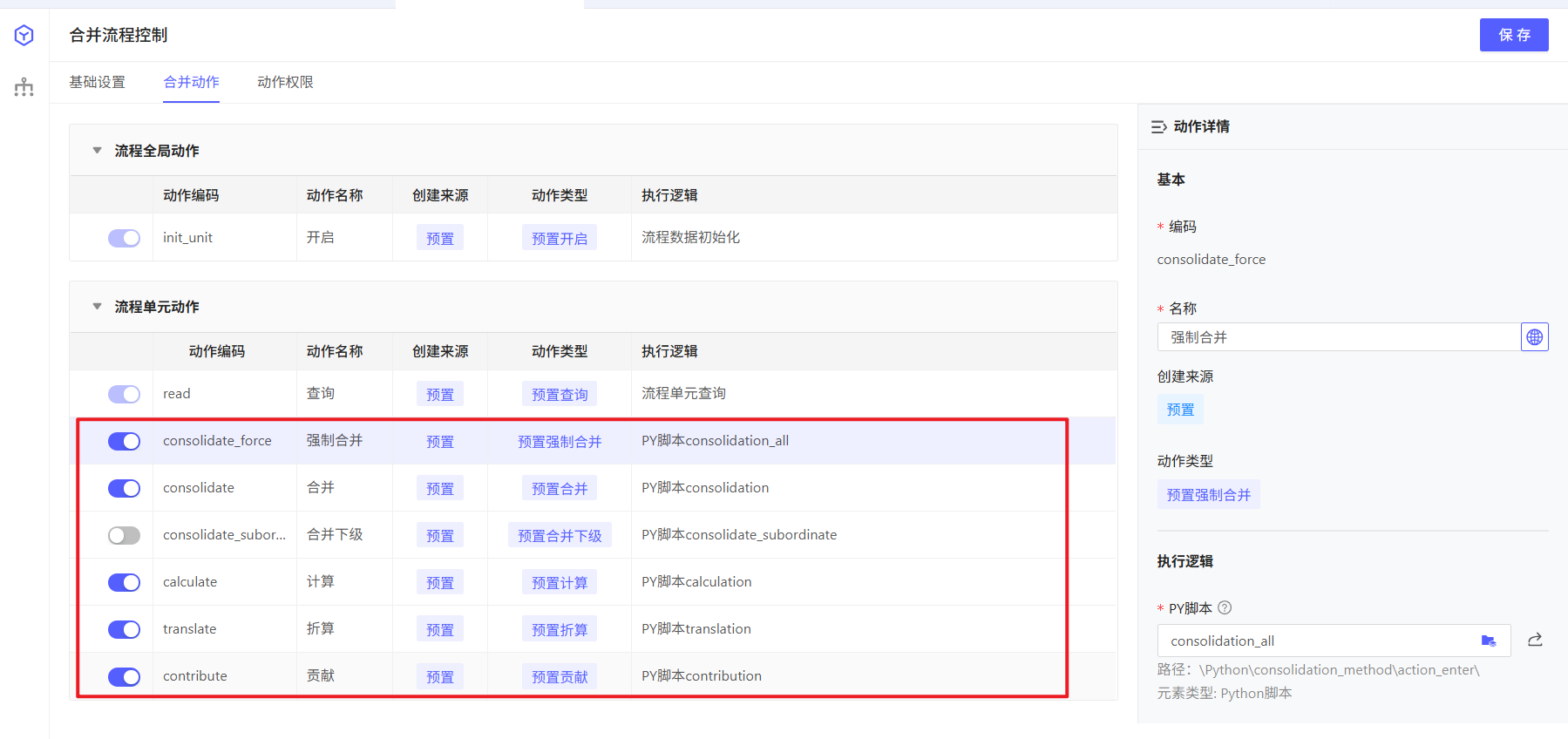
相关的py文件
2.3 合并调度与自定义脚本的关系
合并调度逻辑仅提供算法入口及部分Value的标准结转逻辑,具体业务逻辑由自定义脚本提供。
|
算法入口 |
Entity范围 |
Value范围 |
涉及规则 |
说明 |
|---|---|---|---|---|
|
计算 |
当前单位 |
EC ECA |
rule.py: def calculate() |
适用于单体公司或合并节点在不同的本币上计算报表数据 |
|
折算 |
当前单位 |
PC PCA |
rule.py: def translate() |
适用于将该节点的本币数据折算至父币 |
|
贡献 |
当前单位 |
Parent |
调度:Parent结转 |
适用于计算该节点向父级贡献的金额 |
|
当前单位 |
PA |
rule.py: def calculate() | ||
|
当前单位 |
Proportion |
rule.py: def consolidate() | ||
|
强制合并 |
下级单位
|
所有 |
计算+折算+贡献 |
适用于重算合并下属所有单位数据并执行合并汇总的场景 |
|
当前单位 |
EC |
调度/钩子函数:EC结转到合并 | ||
|
当前单位 |
EC ECA |
rule.py: def calculate() | ||
|
合并 |
下级单位
|
所有 |
有条件执行:计算+折算+贡献
|
取决于下级单位是否已执行过计算+折算+贡献 |
|
当前单位 |
EC |
调度/钩子函数:EC结转到合并 | ||
|
当前单位 |
EC ECA |
rule.py: def calculate() | ||
|
合并子级 |
子级单位
|
所有 |
计算+折算+贡献 |
适用于重算合并子级单位数据并执行合并汇总的场景 |
|
当前单位 |
EC |
调度/钩子函数:EC结转到合并 | ||
|
当前单位 |
EC ECA |
rule.py: def calculate() | ||
|
合并执行前 |
无 |
无 |
钩子函数 |
初始化一些自定义对象数据 |
|
合并整体执行完成后 |
成功单位 |
无 |
钩子函数 |
可考虑将校验放到此处,以提升合并效率 |
|
合并整体执行失败后 |
失败单位 |
无 |
钩子函数 |
一般仅for debug |
简化图示:
含折算场景的合并过程
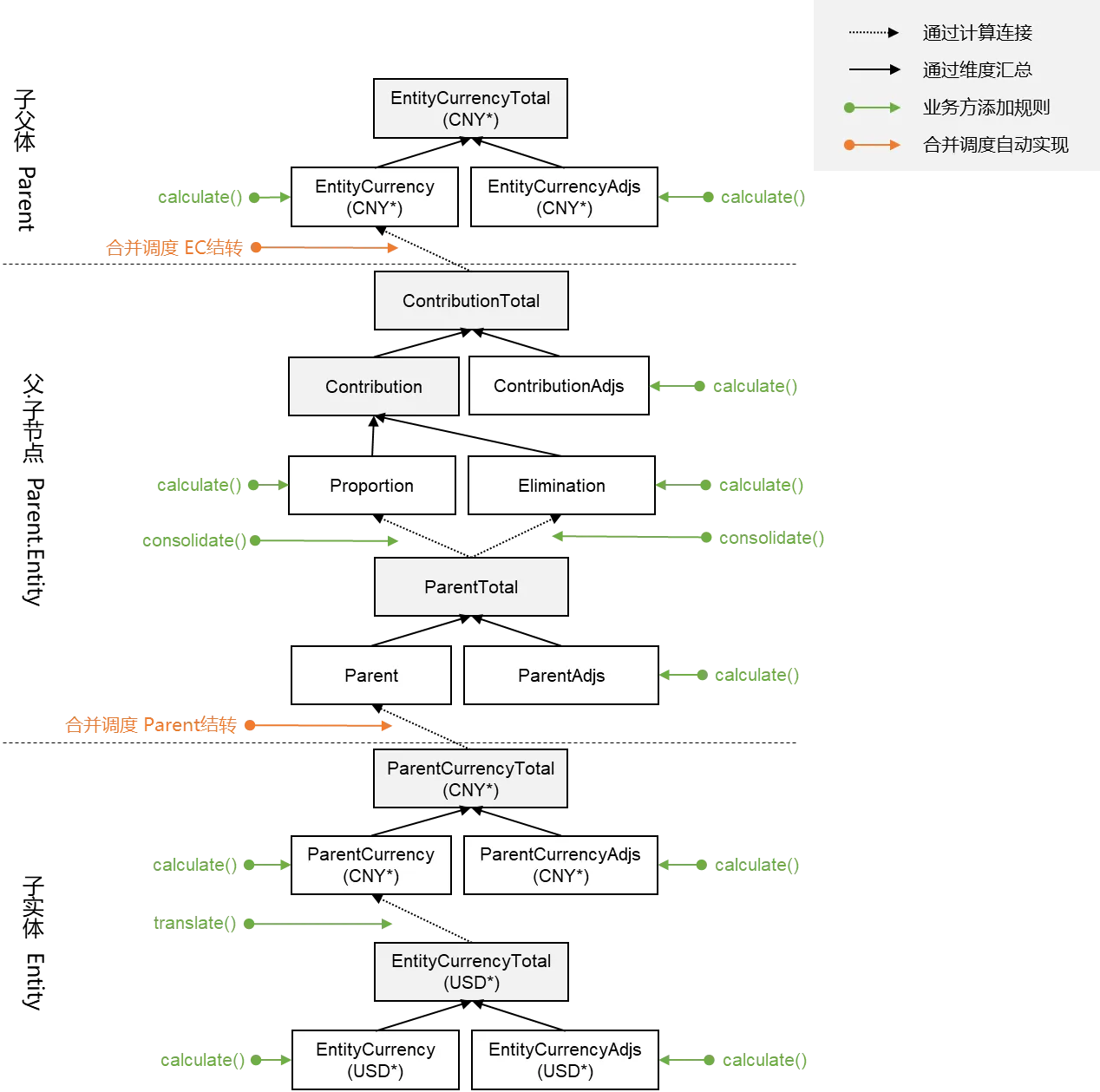
不含折算场景的合并过程
3. 合并算法及相关依赖
3.1 配置信息
1.config.py
config.py记载了合并sdk所需要的模型、数据表、维度路径、日志级别、使用的数据库类型
并可以根据项目实际情况,选择如下配置等:
-
ec_round_num:设定结转小数位数,不设置默认2位,但是建议数据的处理过程中(比如折算、抵销)等都做好小数位控制,以免结转合并EC由于四舍五入出现尾差不平。
-
need_audit_carry:Audittrail维度在合并汇总时结转,方便展示工作底稿。也可自行在proportion维度写规则结转。
-
upward_status_transmission:流程控制状态是否向上传播(点小合并,上级节点状态是否会变成数据变更)
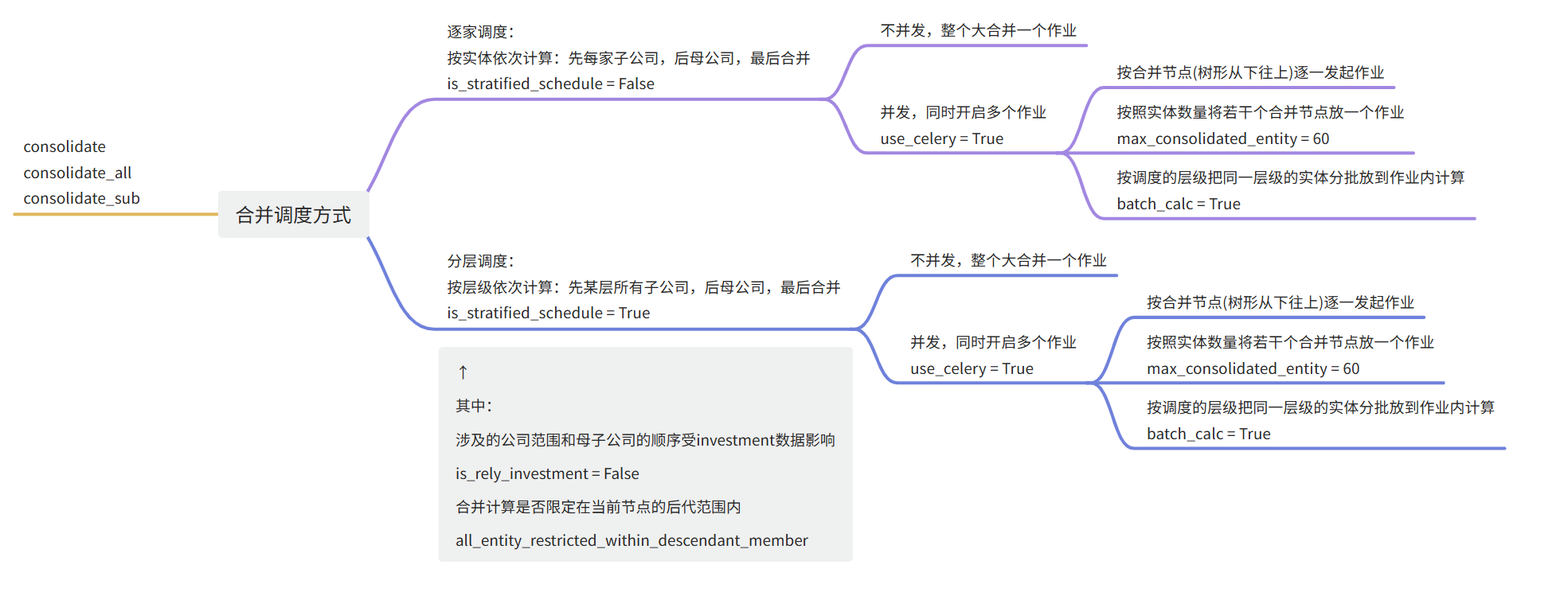
关于调度参数的说明:
实施建议:
为提高合并计算效率,一般开启分层调度和并发(此时entity参数为一个set,会影响rule编写方式),在此前提下,后续并发顺序可根据项目实际情况选择(也可以都试试,rule是通用的),以下供参考:
-
若组织树形比较均匀(各小合并节点下属公司数量差不多):按照并发下的普通模式即可
-
若有较多mini合并节点(小合并节点散且下属公司数量少):可配置max_consolidated_entity
-
若组织树形不太均匀(有些节点公司多,有些节点公司少):可配置batch_calc
2.deepcube_config.py
deepcube_config.py记载了deepcube初始化所需要的一些信息(包括数据库链接信息,目标集范围、来源集范围)。
由于deepcube的一些特性需要指定当前计算的来源集范围,deepcube_config.py主要功能在于自动指定这些信息。
默认配置目标集及来源集
-
在执行计算时以当前情景、当前版本、当前实体、当年以及上一年度的当月、上月、12月的数据为来源集。
-
在执行折算时以当前情景、当前版本、当前实体、当年以及上一年度的当月、上月、12月的数据为来源集。
-
在执行贡献时以当前情景、当前版本、当前实体以及与当前实体有计算依赖关系的实体、当年以及上一年度的当月、上月、12月的数据为来源集。
-
在执行合并时以当前情景、当前版本、当前实体以及与当前实体有计算依赖关系的实体、当年以及上一年度的当月、上月、12月的数据为来源集。
基于此配置文件,财务模型数据初始化以及数据写回封装在合并算法中,无需顾问手工操作,rule.py中的计算、折算、贡献抵销等逻辑都是合并算法整体向deepcube加载一次数据,当业务逻辑执行成功或者业务逻辑遇到异常时候再写入财务模型对应的数据库(为了提升效率 即使是执行合并逻辑也是整体加载数据、整体写入数据库 )。
3.2 执行框架
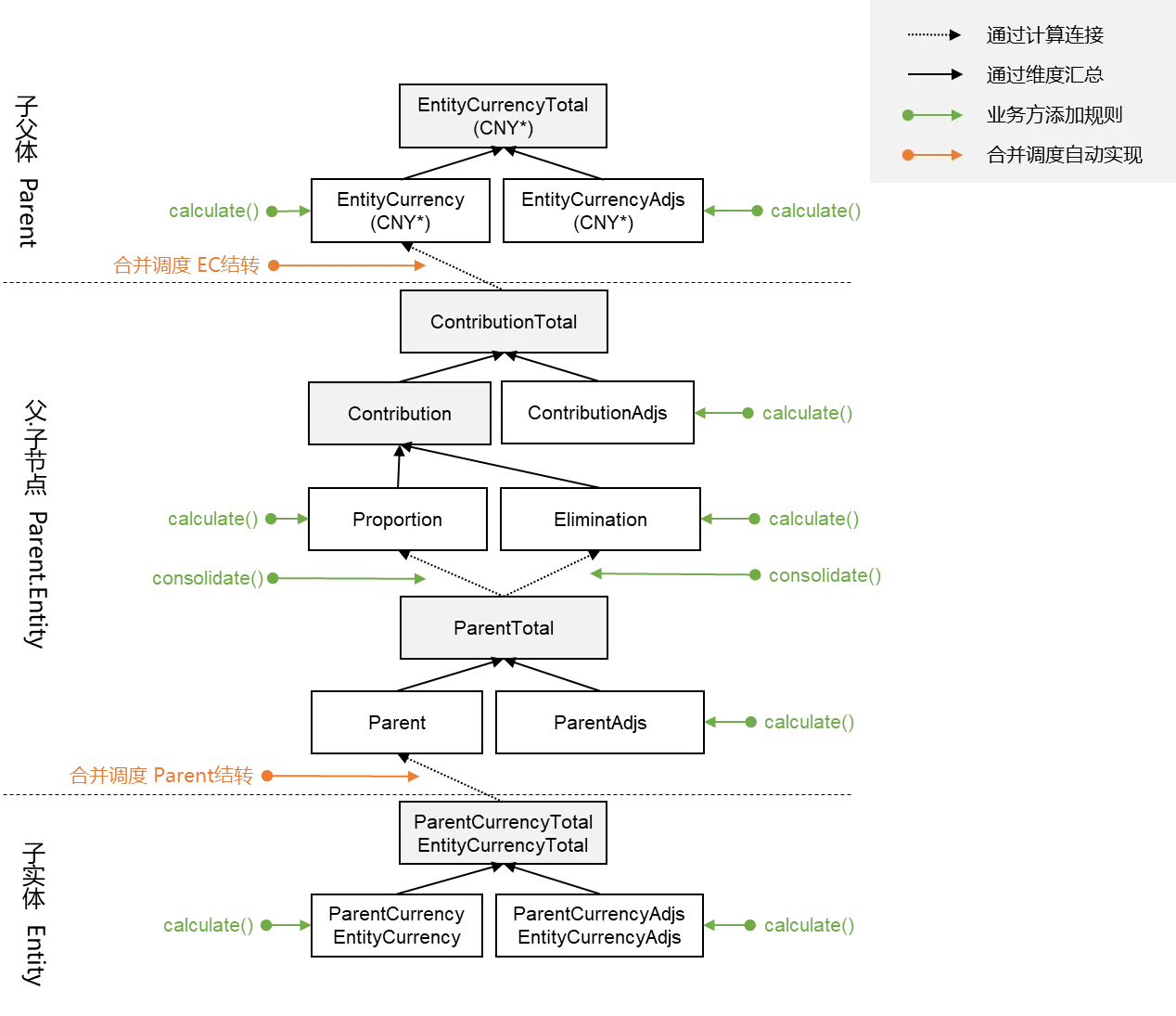
执行框架为合并脚本计算业务逻辑时系统默认设置的按Entity``Value的执行顺序及结转逻辑。标准SDK封装了三个入口:分别是计算入口 Calculation, 折算入口 Translation, 合并入口Consolidation
1.计算入口 - Calculation
适用于单体公司或合并节点计算个别报表数据,从Value角度来看,从EntityCurrency(对于合并节点来说,包括子代ContributionTotal结转到当前合并节点EntityCurrency)计算到EntityCurrencyTotal
由于某些场景下,EntityCurrency的数据依赖EntityCurrencyTotal计算过来,如校验科目,所以系统默认执行两遍。
例如计算E单体公司
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
|---|---|---|---|
|
1 |
E |
EntityCurrency |
calculate() |
|
2 |
E |
EntityCurrencyAdjs |
calculate() |
|
3 |
E |
EntityCurrency |
calculate() |
|
4 |
E |
EntityCurrencyAdjs |
calculate() |
2.折算入口 - Translation
将该节点的本币数据折算至父币,从Value角度来看,如果与父币币种相同,则无需折算,ParentCurrency = EntityCurrncy``ParentCurrencyAdjs = EntityCurrencyAdjs,如果与父币币种不相同,则需要进行折算,ParentCurrency = EntityCurrencyTotal * 汇率
如果EntityCurrency和ParentCurrency不相同,则按如下执行顺序执行
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
|---|---|---|---|
|
1 |
B.E |
ParentCurrency |
translate() |
|
2 |
B.E |
ParentCurrency |
calculate() |
|
3 |
B.E |
ParentCurrencyAdjs |
calculate() |
|
4 |
B.E |
ParentCurrency |
calculate() |
|
5 |
B.E |
ParentCurrencyAdjs |
calculate() |
3.贡献入口 - Contribution
将节点value维度成员为Parent的数据沿着value一路计算至ContributionAdjs,主要是处理合并场景中的抵销相关场景的计算。
value执行顺序
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
B.E |
Parent |
系统标准结转 | |
|
2 |
B.E |
ParentAdjs |
calculate() | |
|
3 |
B.E |
Proportion |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
4 |
B.E |
Proportion |
calculate() | |
|
5 |
B.E |
Elimination |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
6 |
B.E |
Elimination |
calculate() | |
|
7 |
B.E |
ContributionAdjs |
calculate() |
4.合并入口 - Consolidation_all - 按架构逐一调度(非分层调度)
将合并节点从其所有后代逐一合并至本身
Entity执行顺序
假设有如下组织架构,运行的参数为Group节点,其他参数在此场景中忽略,同时考虑组织架构的有效性
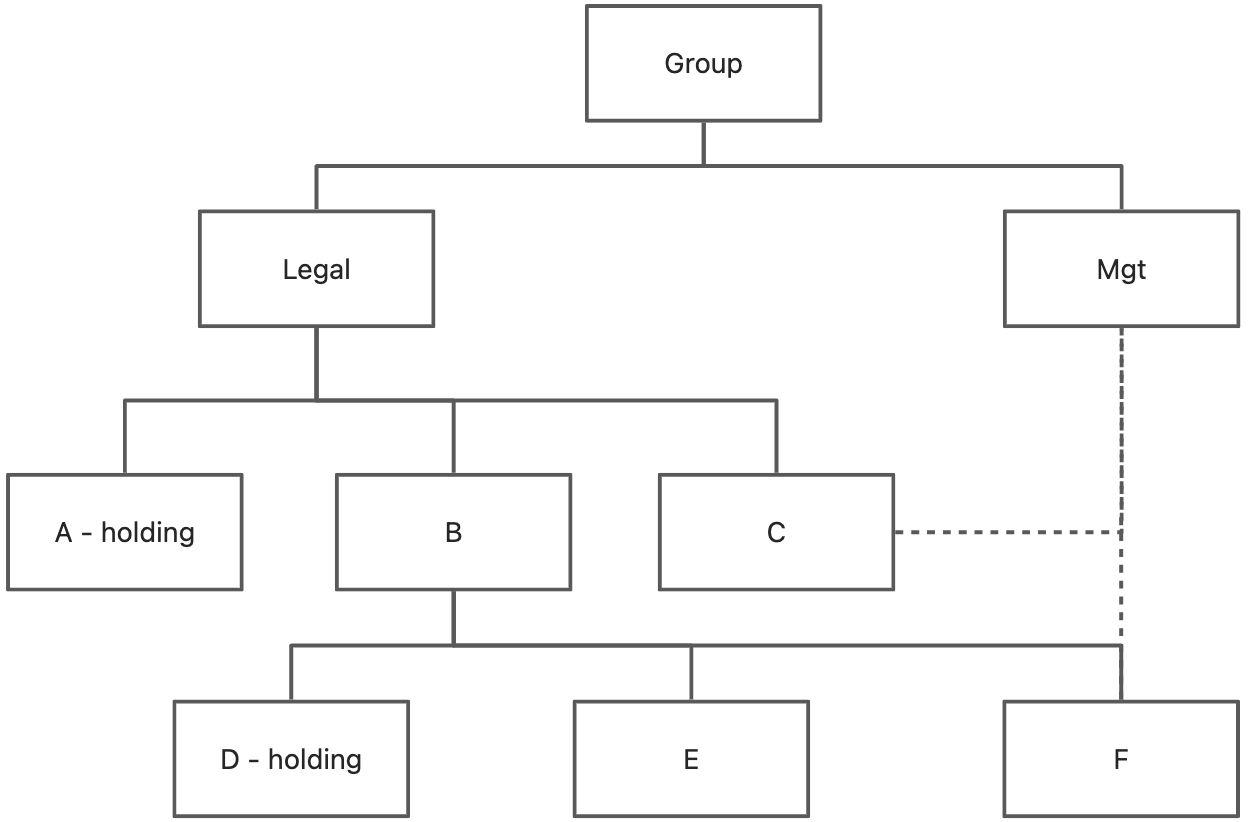
第一步,从入参节点Group开始,找到Legal和Mgt两个前序节点
第二步,从Legal节点开始,找到3个子节点,同时由于A是holding公司(与B、C有控股关系),所以将A变成Legal的前序节点;同时将B和C变成A的前序节点
第三步,从B节点开始,找到3个子节点,同时由于D是holding公司(与E、F有控股关系),所以将D变成B的前序节点;同时将E和F变成B的前序节点
第四步,从Mgt节点开始,找到2个子节点,将C和F变成Mgt的前序节点
最终会形成一个如下的执行顺序图,该图的执行顺序如下:
-
执行图中无前序节点的节点,这几个节点理论上可以支持并行计算
-
执行完后将上述节点从图中移走,并执行上一步
按节点本身(单体)和边(单体往合并节点)展开,如下图
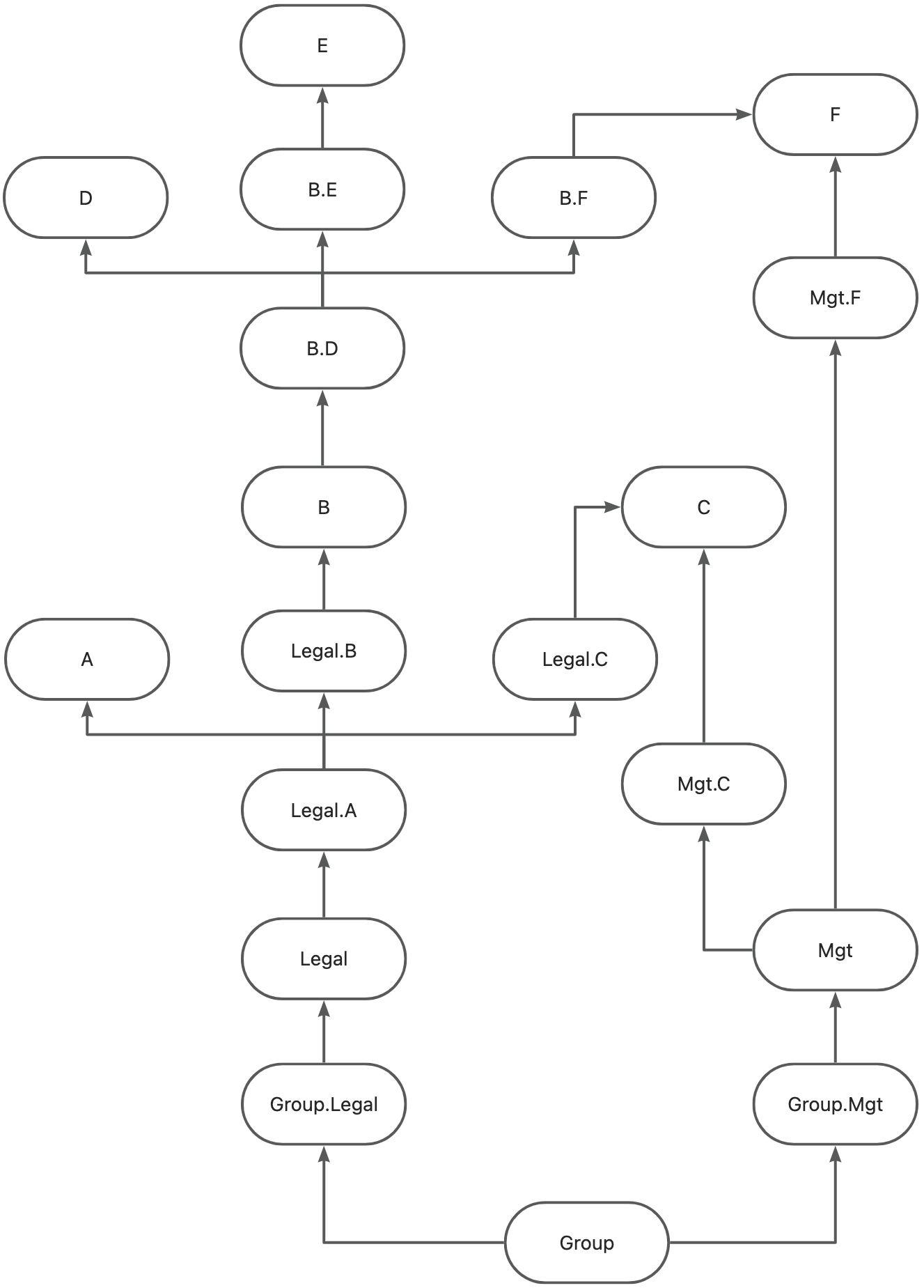
上述执行顺序由python SDK包根据组织架构模型(Entity_Hierarchy)创建生成,此模型为非可选模型
其中如果E持有C部分股权,则演化成如下图
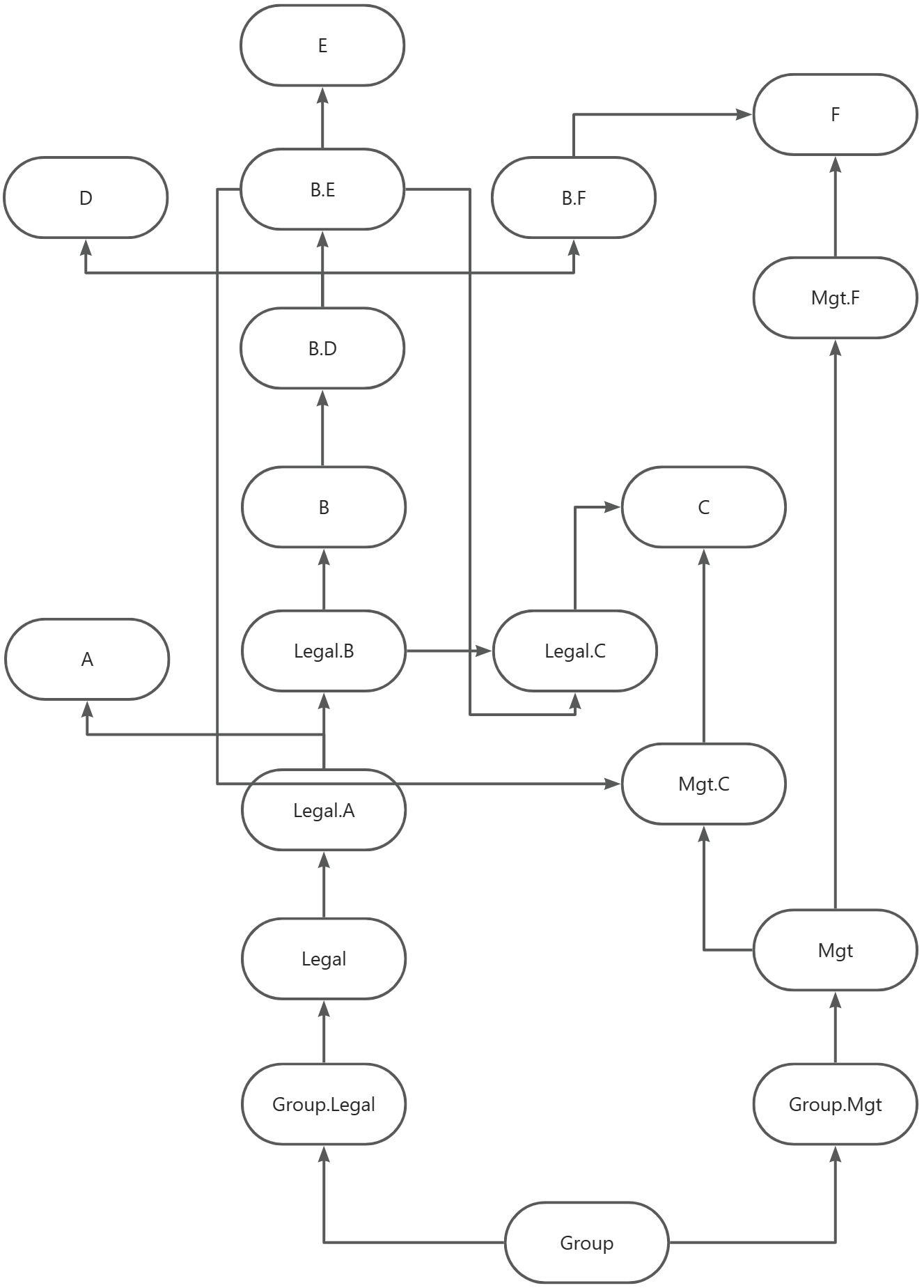
上述执行顺序由python SDK包根据组织架构模型(Investment)创建生成,此模型为可选模型
例如合并B集团,假设F的币种与B的币种不一致
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
E |
EntityCurrency |
calculate() | |
|
2 |
E |
EntityCurrencyAdjs |
calculate() | |
|
3 |
E |
EntityCurrency |
calculate() | |
|
4 |
E |
EntityCurrencyAdjs |
calculate() | |
|
5 |
B.E |
Parent |
系统默认结转 | |
|
6 |
B.E |
ParentAdjs |
calculate() | |
|
7 |
B.E |
Proportion |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
8 |
B.E |
Proportion |
calculate() | |
|
9 |
B.E |
Elimination |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
10 |
B.E |
Elimination |
calculate() | |
|
11 |
B.E |
ContributionAdjs |
calculate() |
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
D |
EntityCurrency |
calculate() | |
|
2 |
D |
EntityCurrencyAdjs |
calculate() | |
|
3 |
D |
EntityCurrency |
calculate() | |
|
4 |
D |
EntityCurrencyAdjs |
calculate() |
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
F |
EntityCurrency |
calculate() | |
|
2 |
F |
EntityCurrencyAdjs |
calculate() | |
|
3 |
F |
EntityCurrency |
calculate() | |
|
4 |
F |
EntityCurrencyAdjs |
calculate() | |
|
5 |
B.F |
ParentCurrency |
translate() | |
|
6 |
B.F |
ParentCurrency |
calculate() | |
|
7 |
B.F |
ParentCurrencyAdjs |
calculate() | |
|
8 |
B.F |
ParentCurrency |
calculate() | |
|
9 |
B.F |
ParentCurrencyAdjs |
calculate() | |
|
10 |
B.F |
Parent |
系统标准结转 | |
|
11 |
B.F |
ParentAdjs |
calculate() | |
|
12 |
B.F |
Proportion |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
13 |
B.F |
Proportion |
calculate() | |
|
14 |
B.F |
Elimination |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
15 |
B.F |
Elimination |
calculate() | |
|
16 |
B.F |
ContributionAdjs |
calculate() |
上述可并发执行,待都执行完成后,执行如下
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
B.D |
Parent |
系统默认结转 | |
|
2 |
B.D |
ParentAdjs |
calculate() | |
|
3 |
B.D |
Proportion |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
4 |
B.D |
Proportion |
calculate() | |
|
5 |
B.D |
Elimination |
consolidate() |
该value可由rule脚本中consolidate函数计算过来 |
|
6 |
B.D |
Elimination |
calculate() | |
|
7 |
B.D |
ContributionAdjs |
calculate() | |
|
8 |
B |
EntityCurrency |
系统标准结转 | |
|
9 |
B |
EntityCurrency |
calculate() | |
|
10 |
B |
EntityCurrencyAdjs |
calculate() | |
|
11 |
B |
EntityCurrency |
calculate() | |
|
12 |
B |
EntityCurrencyAdjs |
calculate() |
总结按公司逐一调度模式下,合并期间规则在Entity和Value上的执行顺序
|
实体顺序 |
序号 |
内容 |
|---|---|---|
|
每个子代重复执行(母公司执行顺序在后-母公司属性通过组织层级模型的”实体类型”字段获取) |
1 |
在 EntityCurrency 和 EntityCurrencyAdjs 上执行calculate() |
|
~~2~~ |
~~ | |
|
3 |
在 ParentCurrency 上执行 translate() | |
|
4 |
在 ParentCurrency 和 ParentCurrencyAdjs 上执行 calculate() | |
|
5 |
将ParentcurrencyTotal结转到Parent
| |
|
6 |
在 ParentAdjs 上执行 calculate() | |
|
7 |
| |
|
8 |
在 Proportion 和 Elimination 上执行 consolidate() | |
|
9 |
在 Proportion 和 Elimination 上执行 calculate() | |
|
10 |
在 ContributionAdjs 上执行 上执行 calculate() | |
|
父代(所有子代都完成后) |
1 |
将每个子实体的 ContributionTotal的合计之和写入到父实体的 EntityCurrency
|
|
2 |
在 EntityCurrency 和 EntityCurrencyAdjs 上执行calculate() |
5.合并入口 - Consolidation_all - 分层调度模式
将合并节点按照一定的顺序按层级合并至本身
Entity执行顺序
假设有如下组织架构,运行的参数为Group节点,其他参数在此场景中忽略,同时考虑组织架构的有效性
第一步,从入参节点Group开始,找到所有的末级单体节点
第二步,从后往前数,找到倒数第二层的合并节点B和Mgt
第三步,从后往前数,找到倒数第三层的合并节点Legal
第四步,从后往前数,找到倒数第四层的合并节点Group
最终会形成一个如下的执行顺序图,按节点本身(单体)和边(单体往合并节点)展开,如下图
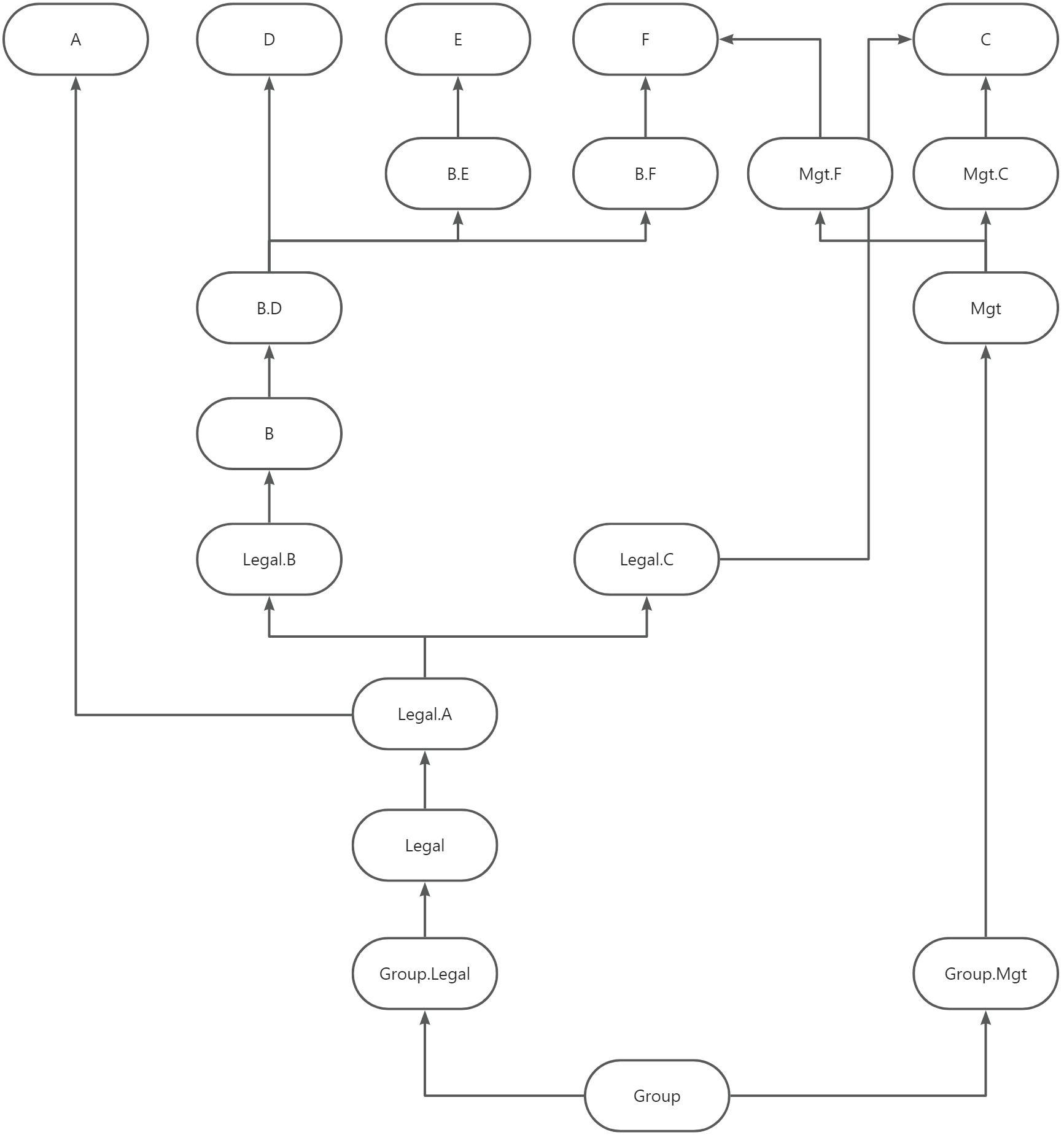
上述执行顺序由python SDK包根据组织架构模型(Entity_Hierarchy)创建生成,此模型为非可选模型
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
A D E F C |
EntityCurrency |
calculate() | |
|
2 |
EntityCurrencyAdjs |
calculate() | ||
|
3 |
EntityCurrency |
calculate() | ||
|
4 |
EntityCurrencyAdjs |
calculate() |
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
B.E B.F |
Parent |
系统默认结转 | |
|
2 |
ParentAdjs |
calculate() | ||
|
3 |
Proportion |
consolidate() | ||
|
4 |
Proportion |
calculate() | ||
|
5 |
Elimination |
consolidate() | ||
|
6 |
Elimination |
calculate() | ||
|
7 |
ContributionAdjs |
calculate() | ||
|
8 |
B.D |
Parent |
系统默认结转 | |
|
9 |
ParentAdjs |
calculate() | ||
|
10 |
Proportion |
consolidate() | ||
|
11 |
Proportion |
calculate() | ||
|
12 |
Elimination |
consolidate() | ||
|
13 |
Elimination |
calculate() | ||
|
14 |
ContributionAdjs |
calculate() | ||
|
15 |
B |
EntityCurrency |
系统默认结转合并EC | |
|
16 |
EntityCurrency |
calculate() | ||
|
17 |
EntityCurrencyAdjs |
calculate() | ||
|
18 |
EntityCurrency |
calculate() | ||
|
19 |
EntityCurrencyAdjs |
calculate() |
|
执行顺序 |
Entity |
Value |
对应执行的脚本函数 |
备注 |
|---|---|---|---|---|
|
1 |
Legal.B |
Parent |
系统默认结转 | |
|
2 |
ParentAdjs |
calculate() | ||
|
3 |
Proportion |
consolidate() | ||
|
4 |
Proportion |
calculate() | ||
|
5 |
Elimination |
consolidate() | ||
|
6 |
Elimination |
calculate() | ||
|
7 |
ContributionAdjs |
calculate() | ||
|
8 |
Legal.A |
Parent |
系统默认结转 | |
|
9 |
ParentAdjs |
calculate() | ||
|
10 |
Proportion |
consolidate() | ||
|
11 |
Proportion |
calculate() | ||
|
12 |
Elimination |
consolidate() | ||
|
13 |
Elimination |
calculate() | ||
|
14 |
ContributionAdjs |
calculate() | ||
|
15 |
Legal |
EntityCurrency |
系统默认结转合并EC | |
|
16 |
EntityCurrency |
calculate() | ||
|
17 |
EntityCurrencyAdjs |
calculate() | ||
|
18 |
EntityCurrency |
calculate() | ||
|
19 |
EntityCurrencyAdjs |
calculate() |
分层调度模式相比非分层调度模型,能够好的利用向量化的能力,但是相应的写法上灵活度会下降一些(比如,计算中需要用到entity作为判断,就需要自定义一个cur_entity变量在Entity_set内循环遍历)。
6.合并入口 - Consolidation
与Conoldation_all的逻辑基本一致,区别在于会跳过已经计算成功/折算成功/贡献成功的节点,实现增量合并的功能。
7.合并入口 - Consolidation_subordinate
与Conoldation_all的逻辑基本一致,区别在于只执行当前合并节点直接下级的折算、贡献、结转EC以及当前合并节点的计算,合并下级的调度顺序也会考虑诸如是否母公司、投资关系的影响。
3.3 并发
如果要启用celery并发(合并算法 2.6.16版本以上功能)需要在config.py文件中做如下设置:
# 是否使用celery
config.use_celery = False
# 最大celery并发数
config.max_celery_concurrency = 4
当前的并发调度模式基于计算耗时和初始化耗时的妥协,基本模式为将大合并拆成小合并并发执行。
相当于先执行执行顺序图中的层级较低的合并节点,再执行层级相对较高的合并节点(前提是该合并节点下的合并节点已执行完毕)。
另:celery并发调度模式无法本地执行,本地debug需要将use_celery设为false
2.6.2.21版本中增加max_consolidated_entity配置项 ,用来限制celery进行并发调度模式下一次合并最多跑多少个合并实体。增加这一配置项主要出于:如果把大合并拆成最低层级小合并跑,有可能在小合并作业初始化过程中耗时过多(一般要5000毫秒甚至更多),增加这一配置后相当于把大合并拆成层级较高的合并,初始化耗时相对少一点。
# 使用celery进行并发调度情况下 一次合并最多跑多少个合并实体
config.max_consolidated_entity = 32
3.4 合并流程状态回写
在流程控制中,系统为每个场景``版本``年``月下的entity提供了三个标准状态:
-
计算状态
-
折算状态
-
贡献状态
状态修改逻辑:
-
执行计算、折算、贡献时,合并算法会先将对应状态修改为未计算、未折算、未贡献,当逻辑执行完毕后再修改为已计算、已折算、已贡献。
-
当执行合并时,合并算法会在合并开始时将流程状态修改为未计算、未折算、未贡献,当单个entity对应逻辑执行完毕后再修改为已计算、已折算、已贡献。
3.5 自定义脚本
该python文件遵循如下约束:
-
在custom目录下
-
文件名为rule.py
-
rule.py必须实现了
calculate``translate``consolidate函数
该脚本定位使用用户为业务顾问,在脚本中编写简单的逻辑条件语句``循环控制语句即可,描述具体业务逻辑时应使用deepcube相关计算功能。
回到顶部
咨询热线
400-821-9199
