9.4合并算法通用示例
1.校验规则
针对不同的value,有不同的校验需求,因此,需要将value作为判断条件。
注意校验科目和通用维度与流程控制模型中配置保持一致。
如果是非强制校验科目,可以在rule中计算,但是不放到流程控制中进行卡控。
在流程控制中配置的科目,若不参与校验,在rule中赋值为0。(null在流程控制中视为未校验)
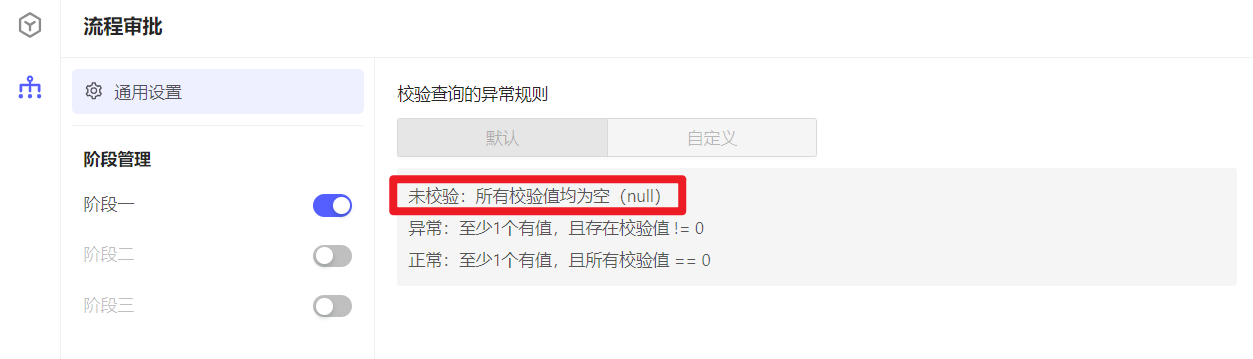
脚本示例:
单家校验(未开启分层调度下使用):
## 第二次计算时执行校验
if dc.calc_second_flag:
if dc.cur_value == 'EntityCurrency':
print('执行校验')
main_cube.clear_data(account['Validation'].Base(), *none_pov)
main_cube.loc[(account['V001'], *none_pov)] = main_cube.loc[(
account['BS1n2'], *total_pov)] - main_cube.loc[(account['BS3n4'], *total_pov)] + 0
因为在deepcube中如果加减法等号两侧都是Null时 计算结果也是Null。合并流程组件审批前校验逻辑认为:null是未校验,0是已校验并正确。因此,这种情况下如果要把Null当零处理,需要在右侧补零(+0)。
批量校验(放于合并执行后的钩子函数):
if dc.calc_second_flag:
#当执行目标节点后完后执行校验(如果执行的是合并逻辑目标节点就是合并节点 如果是计算逻辑 目标节点就是当前计算节点)
if dc.cur_value == 'EntityCurrency' and dc.target_vertex == dc.cur_entity:
# 批量执行校验
print('执行校验')
print(dc.target_vertex)
print(dc.cur_entity)
# 拿到所有跑完逻辑的实体
completed_entity = dc.p2['completed_entity']
completed_entity.add(dc.cur_entity)
# 拿到纯子代的实体
completed_entity = [i for i in completed_entity if not re.match(PARENT_CHILD_PARSE, i)]
print(completed_entity)
# 把上述实体放到scope中
main_cube.scope(en[completed_entity])
main_cube.clear_data(ac['Validation'].Base(), *none_pov)
main_cube.loc[(ac['V001'], *none_pov)] = main_cube.loc[(
ac['BS1n2'], *total_pov)] - main_cube.loc[(ac['BS3n4'], *total_pov)] + 0
main_cube.loc[(ac['V002'], *none_pov)] = 0
main_cube.loc[(ac['V003'], *none_pov)] = 0
在多数情况批量校验要比单家校验性能更好。
2.重分类规则
-
重分类逻辑
if dc.cur_value == 'EntityCurrencyAdjs':
if dc.entity_is_base:
print("执行重分类")
main_cube.clear_data(audittrail['RECL_ADJ02'])
main_cube.loc[(audittrail['RECL_ADJ02'], account['220299'], movement['BAL'], *d_none_pov)] = \
main_cube.loc[(audittrail['RECL_ADJ02'], account['220299'], movement['BAL'], *d_none_pov)] + \
main_cube.loc[
(account['2202'],
audittrail['DRAFT'], value['EntityCurrency'], movement['BAL'], *d_none_pov)].loc[
main_cube.data < 0] * (-1)
main_cube.loc[(audittrail['RECL_ADJ02'], account['112299'], movement['BAL'], *d_none_pov)] = \
main_cube.loc[(audittrail['RECL_ADJ02'], account['112299'], movement['BAL'], *d_none_pov)] + \
main_cube.loc[
(account['2202'],
audittrail['DRAFT'], value['EntityCurrency'], movement['BAL'], *d_none_pov)].loc[
main_cube.data < 0] * (-1)
main_cube.loc[(audittrail['RECL_ADJ02'], account['112299'], movement['BAL'], *d_none_pov)] = \
main_cube.loc[(audittrail['RECL_ADJ02'], account['112299'], movement['BAL'], *d_none_pov)] + \
main_cube.loc[
(account['1122'],
audittrail['DRAFT'], value['EntityCurrency'], movement['BAL'], *d_none_pov)].loc[
main_cube.data < 0] * (-1)
main_cube.loc[(audittrail['RECL_ADJ02'], account['220299'], movement['BAL'], *d_none_pov)] = \
main_cube.loc[(audittrail['RECL_ADJ02'], account['220299'], movement['BAL'], *d_none_pov)] + \
main_cube.loc[
(account['1122'],
audittrail['DRAFT'], value['EntityCurrency'], movement['BAL'], *d_none_pov)].loc[
main_cube.data < 0] * (-1)
reclass_journal_df = main_cube.loc[
(audittrail['RECL_ADJ02'], account[['112299', '220299']], movement['BAL'], partner.root.Base(),
*d_none_pov)].to_dataframe()
print('往来重分类')
这里写了个应收应付负数重分类的逻辑,本质上是利用了deepcube可以按照模型数据做筛选(筛选负数)的能力,不需要做大批量的循环。
-
自动生成凭证
-
将凭证数据存入dc
-
reclass_journal_df = main_cube.loc[
(audittrail['RECL_ADJ02'], account[['112299', '220299']], movement['BAL'], partner.root.Base(),
*d_none_pov)].to_dataframe()
print('往来重分类')
print(reclass_journal_df)
dc.append_calc_journal(reclass_journal_df, '往来重分类')
本质上是把调整过的数据查出来存到dc中
- 生成凭证
import re
import pandas as pd
from Python.common.common_tools import PARENT_CHILD_PARSE, parse_parent
from Python.deep_consol.deep_consol import deep_consol as dc
from Python.deep_consol.journal_model import journal_model
def custom_process_control_post_python(p2):
if p2.get("completed_entity"):
t = journal_model.table
where = ((t.year == p2['year']) &
(t.period == p2['period']) &
(t.scenario == p2['scenario']) &
(t.version == p2['version']) &
(t.value.isin(["Elimination", 'EntityCurrencyAdjs']))) & \
(t.entity.isin(p2.get("completed_entity")))
r = journal_model.delete(where)
print(r)
# 构造凭证
rlt = dc.journal_data()
def get_consol_name(row):
consol = ''
if re.match(PARENT_CHILD_PARSE, row['entity']):
consol = parse_parent(row['entity'])
return pd.Series({'consol': consol})
head_df = rlt[0]
line_df = rlt[1]
head_df['consol'] = head_df.apply(get_consol_name, axis=1)
print(line_df)
print(head_df)
# 存入凭证模型
if not head_df.empty and not line_df.empty:
head_df['_type'] = 'sys_journal'
r = journal_model.save(head_df=head_df,
line_df=line_df,
)
print(r)
在后置钩子函数中生成相关凭证。
总体来说,现在配合deepcube使用的合并算法只能是先将数据写入deepcube deepcube再写入模型,然后生产凭证仅做备查(不需要过账)。
3.期初结转规则
1、期初结转
main_cube.clear_data(movement['OPN'])
main_cube.loc[movement['OPN']] = main_cube.loc[(*last_pov, movement['CLO'])]
具体科目范围、审计线索范围需要在scope里做限制
2、年初未分配利润结转
main_cube.loc[movement['OPN'], account['410411']] = main_cube.loc[
(*last_pov, account['4104'], movement['CLO'])]
3、本年利润结转
## 利润结转:410301本年利润=PL60000000归母净利润
## 清除数据
main_cube.clear_data({"account": account["410301"]})
## 除了原始数据,其他审计路径上都计算
main_cube.scope({"audittrail":audittrail["Report"].Base() - audittrail["DRAFT"].Base()}):
main_cube.loc[account["410301"],movement["INC", "BAL"]] = cube1.loc[account["PL60000000"]]
4.折算规则
报表折算包括科目余额表、三大报表及相关附注报表在内的报表折算逻辑。包括期初、增加、减少、余额的折算逻辑处理,汇兑差异的处理,股权等特殊科目的业务处理,也包括一些业务指标的特殊折算处理等。
需要注意的是交易币种转化为本位币的账务折算处理不在本模块范围内
4.1 获取汇率逻辑
如果当前Entity维度了汇率,则取当前汇率,否则,取No_Entity汇率。
汇率数据维护见文档
脚本示例:
def get_rate(rate_type):
# 优先取本公司汇率,若无取NoEntity汇率
rate_pov = (
exr_year[cur_year],
exr_scenario[cur_scenario],
exr_version[cur_version],
exr_period[cur_period],
exr_entity[cur_entity],
)
ex_rate_cube.clear_scope()
ex_rate_cube.scope(*rate_pov)
df_a = ex_rate_cube.loc[
exr_entity[dc.cur_entity], exr_fc[dc.local_currency], exr_tc[dc.parent_currency], exr_account[
rate_type]].to_dataframe()
df_b = ex_rate_cube.loc[
exr_entity["NoEntity"], exr_fc[dc.local_currency], exr_tc[dc.parent_currency], exr_account[
rate_type]].to_dataframe()
if df_a.empty:
if df_b.empty:
return None
else:
return df_b['decimal_val'][0]
else:
return df_a['decimal_val'][0]
def translate():
ave_rate = get_rate("AveRate")
clo_rate = get_rate("CloRate")
opn_rate = get_rate("OpnRate")
4.2 折算方法-按YTD折算
执行前提:
针对ParentCurrency与EntityCurrency币种不同的情况下,方执行通用折算逻辑,通用折算逻辑计算目标锁定在V#ParentCurrency一个成员上。
按YTD折算(此时平均汇率代表年度平均汇率)
|
条件 |
Movement | ||||
|---|---|---|---|---|---|
|
科目类型 |
OPNInt |
OPNADJ |
INC/DEC |
ExDiff |
BAL/NoMov |
|
Balance/Flow |
=上年期末PC |
=ECT |
=ECT |
NA |
=ECT |
|
长投&商誉 |
=上年期末PC |
=ECT*期初汇率 |
=ECT* 期末汇率/历史汇率 |
NA |
=期初PC+变动PC |
|
一般Asset/Liability |
=上年期末PC |
=ECT*期初汇率 |
=ECT*平均汇率 |
倒减 |
=ECT*期末汇率 |
|
年初未分配利润 |
=上年期末未分配利润PC |
=ECT*期初汇率 |
NA |
NA |
=期初PC+变动PC |
|
本年利润/利润分配 |
NA |
=ECT*期初汇率 |
=ECT*平均汇率 |
NA |
=期初PC+变动PC |
|
一般Equity |
=上年期末PC |
=ECT*期初汇率 |
=ECT* 期末汇率/历史汇率 |
NA |
=期初PC+变动PC |
|
Rvenue/Expense |
NA |
NA |
=ECT*平均汇率 |
NA |
=ECT*平均汇率 |
|
OCI(外币折算差额) |
=上年期末PC |
NA |
NA |
倒减 |
=资产PC-负债PC-权益PC |
def translate():
pov = (
year[cur_year],
scenario[cur_scenario],
version[cur_version],
period[cur_period],
entity[cur_entity],
value[dc.cur_value],
view['YTD']
)
main_cube.clear_scope()
main_cube.scope(*pov)
main_cube.clear_data(account['#root'].Base()) # 先清数,调度里没
ave_rate = get_rate("AveRate")
clo_rate = get_rate("CloRate")
opn_rate = get_rate("OpnRate")
asset_liability_account = account.loc[account.attr('accounttype').isin(['ASSET', 'LIABILITY'])]
equity_account = account.loc[account.attr('accounttype').isin(['EQUITY'])]
pl_account = account.loc[account.attr('accounttype').isin(['REVENUE', 'EXPENSE'])]
other_account = account.loc[account.attr('accounttype').isin(['FLOW', 'BALANCE'])]
if opn_rate:
main_cube.loc[asset_liability_account, movement['OPN'].Base()] = \
main_cube.loc[value[dc.local_currency_total]] * opn_rate
if ave_rate:
main_cube.loc[pl_account] = main_cube.loc[value[dc.local_currency_total]] * ave_rate
main_cube.loc[asset_liability_account, movement[['INC', 'DEC']]] = \
main_cube.loc[value[dc.local_currency_total]] * ave_rate
if clo_rate:
main_cube.loc[asset_liability_account, movement['BAL']] = \
main_cube.loc[value[dc.local_currency_total]] * clo_rate
main_cube.loc[asset_liability_account, movement['ExDiff']] = main_cube.loc[movement['BAL']] - main_cube.loc[
movement['OPNInt']] - main_cube.loc[movement['INC']] + main_cube.loc[movement['DEC']]
# other account
main_cube.loc[other_account] = main_cube.loc[value[dc.local_currency_total]] * 1
pass
4.3 折算方法-按PVA折算
PVA折算:与YTD折算的区别是,结算流量类指标时,使用的是每月发生额*每月平均汇率
|
条件 |
Movement | ||||
|---|---|---|---|---|---|
|
科目类型 |
OPNInt |
OPNADJ |
INC/DEC |
ExDiff |
BAL/NoMov |
|
Balance/Flow |
=上年期末PC |
=ECT |
=ECT |
NA |
=ECT |
|
长投&商誉 |
=上年期末PC |
=ECT*期初汇率 |
=上月PC+本月ECT* 期末汇率/历史汇率 |
NA |
=期初PC+变动PC |
|
一般Asset/Liability |
=上年期末PC |
=ECT*期初汇率 |
=上月PC+本月ECT*平均汇率 |
倒减 |
=ECT*期末汇率 |
|
年初未分配利润 |
=上年期末未分配利润PC |
=ECT*期初汇率 |
NA |
NA |
=期初PC+变动PC |
|
本年利润/利润分配 |
NA |
=ECT*期初汇率 |
=上月PC+本月ECT*平均汇率 |
NA |
=期初PC+变动PC |
|
一般Equity |
=上年期末PC |
=ECT*期初汇率 |
=上月PC+本月ECT* 期末汇率/历史汇率 |
NA |
=期初PC+变动PC |
|
Rvenue/Expense |
NA |
NA |
=上月PC+本月ECT*平均汇率 |
NA |
=上月PC+本月ECT*平均汇率 |
|
OCI(外币折算差额) |
=上年期末PC |
NA |
NA |
倒减 |
=资产PC-负债PC-权益PC |
5.一般抵销规则
5.1抵销时不轧差
-
假设 : 对账阶段都已经对平
-
总体逻辑:按原科目写直接写负数金额
-
两种抵销范围的逻辑
-
最小共父逻辑
-
pl_df = main_cube.loc[account['PL'].Base(), partner['Internal'].Base(), value['ParentTotal'], audittrail[
'REPORT'], movement['BAL']].to_dataframe()
for index, row in pl_df.iterrows():
if dc.EntityMD.parent() in dc.EntityMD.common_ancestor(row['partner'], row['entity']):
dc.con(row=row, dest=(
audittrail['REVCOS_ELIM'],
value["Elimination"]
), factor=-1, nature='内部交易抵销')
2. icp属于合并范围内
pl_df = main_cube.loc[account['PL'].Base(), partner['Internal'].Base(), value['ParentTotal'], audittrail[
'REPORT'], movement['BAL']].to_dataframe()
for index, row in pl_df.iterrows():
# 按行迭代判断
if dc.EntityMD.is_descendant(dc.EntityMD.parent(), row['partner']):
dc.con(row=row, dest=(
audittrail['REVCOS_ELIM'],
value["Elimination"]
), factor=-1, nature='内部交易抵销')
or
partner_set = set(dc.EntityMD.list(cur_entity_parent, 'descendant'))
df = main_cube.loc[account['BS'].Base(), partner[partner_set], value['ParentTotal'], audittrail[
'REPORT'], movement['BAL']].to_dataframe()
## 取数范围直接限制为合并范围内 这样少一些循环效率 要更高一点
dc.con(row=df, dest=(
audittrail['INTERCO_ELIM'],
value["Elimination"]
), factor=-1, nature='关联往来抵销')
3. 两种算法优劣:
最小共父的逻辑是比较符合合并算法中图论的相关概念的,相对来说比较科学的,但是找共父的这个逻辑相对耗时(涉及到递归,尽管加了一些缓存但是如果层级较深也有不少的耗时)
ICP属于合并范围内这个判断逻辑在逐层合并的情况下其实是近似实现了最小共父的逻辑,性能消耗也相对小一点
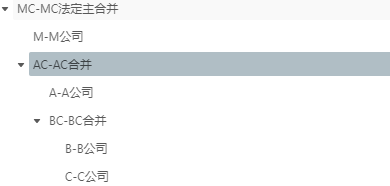
举例:比如当前在跑MC合并 ,M与B有关联交易。
按照最小共父的抵销规则M与B关联交易 M的相关数据会这 MC.M条边进行抵销,而 B的相关数据会在MC.AC这条边进行抵销。
按照ICP属于合并范围内的逻辑也能实现一样的效果,区别在于如果在MC.AC这条边的ICP交易数据还有B对C的交易按照ICP属于合并范围内的逻辑也会进行抵销(逻辑上来说正常情况下B对C的交易已经在BC节点的两条边上进行抵销了 贡献上来的数据不应该有这些数据)。
5.2按plug_account轧差
-
假设 : 对账阶段都已经对平
-
总体逻辑:除了常规按负数直接写金额,还需要向plug_account写数。注意不同accout type写入plug_account的符号的处理
df = main_cube.loc[(account['2202'].Base() + account['1122'].Base(), entity[entity_list], partner[entity_list],
value['EntityCurrencyTotal'],
audittrail['REPORT'], movement['BAL'], *d_none_pov)].to_dataframe()
for index, row in df.iterrows():
if dc.EntityMD.is_base(dc.cur_entity, row['entity']) or row['entity'] == dc.cur_entity_child:
if dc.EntityMD.parent() in dc.EntityMD.common_ancestor(row['partner'], row['entity']):
dc.con(row=row, dest=(entity[dc.cur_entity],
audittrail['INTERCO_ELIM'],
value["Elimination"]
), factor=-1, nature='关联往来抵销')
if row['account'].startswith('2202'):
dc.con(row=row, dest=(account['PLUG01'],
audittrail['INTERCO_ELIM'],
value["Elimination"]
), factor=1, nature='关联往来抵销')
elif row['account'].startswith('1122'):
dc.con(row=row, dest=(account['PLUG01'],
audittrail['INTERCO_ELIM'],
value["Elimination"]
), factor=-1, nature='关联往来抵销')
效果差不多是这样的:

差异金额会被放到plug_account中
5.3按对方金额轧差
-
假设 : Parent、ParentAdjs 不会做特殊调整、抵销场景也相对简单
-
总体逻辑:
-
这里举一个按大抵的逻辑
-
建立分组(示例代码的分组是按照2202、1122科目建立的分组,实际情况可能更加复杂)并取相关数据(Entity和ICP的取数范围是当前实体的parent的所有base节点,这里不太方便取父.子节点取Parent,因为可能存在多父可能还得针对这种情况去做去重)
-
先做正常的抵销
-
再做额外的处理逻辑(简单来说就是查对方科目的金额跟我方科目金额做比较,如果大于我们金额就做相应的调整,con函数会做相应的聚合,实现按大抵销的逻辑)
-
-
entity_list = dc.EntityMD.list(dc.EntityMD.parent(), 'base')
df = main_cube.loc[(account['2202'].Base() + account['1122'].Base(), entity[entity_list], partner[entity_list],
value['EntityCurrencyTotal'],
audittrail['REPORT'], movement['BAL'], *d_none_pov)].to_dataframe()
for index, row in df.iterrows():
# 先抵销我对别人的
if dc.EntityMD.is_base(dc.cur_entity, row['entity']) or row['entity'] == dc.cur_entity_child:
if dc.EntityMD.parent() in dc.EntityMD.common_ancestor(row['partner'], row['entity']):
dc.con(row=row, dest=(entity[dc.cur_entity],
audittrail['INTERCO_ELIM'],
value["Elimination"]
), factor=-1, nature='关联往来抵销')
df1 = main_cube.loc[(account['2202'], entity[entity_list], partner[entity_list], value['EntityCurrencyTotal'],
audittrail['REPORT'], movement['BAL'], *d_none_pov)].to_dataframe()
for index, row in df1.iterrows():
# 再看别人对我的
if dc.EntityMD.is_base(dc.cur_entity, row['partner']) or row['partner'] == dc.cur_entity_child:
if dc.EntityMD.parent() in dc.EntityMD.common_ancestor(row['partner'], row['entity']):
pov1 = (entity[row['partner']], account['1122'], partner[row['entity']], value['EntityCurrencyTotal'],
audittrail[
'REPORT'], movement['BAL'], *d_none_pov)
data1 = get_cell(pov1)
data2 = row['decimal_val']
if data2 - data1 > 0:
print('kkkkkkkkk')
row['decimal_val'] = data2 - data1
dc.con(row=row, dest=(entity[dc.cur_entity], partner['NoPartner'], account['112299'],
audittrail['INTERCO_ELIM'],
value["Elimination"]
), factor=-1, nature='关联往来抵销')
df2 = main_cube.loc[(account['1122'], entity[entity_list], partner[entity_list], value['EntityCurrencyTotal'],
audittrail['REPORT'], movement['BAL'], *d_none_pov)].to_dataframe()
for index, row in df2.iterrows():
# 再看别人对我的
if dc.EntityMD.is_base(dc.cur_entity, row['partner']):
if dc.EntityMD.parent() in dc.EntityMD.common_ancestor(row['partner'], row['entity']):
pov1 = (entity[row['partner']], account['2202'], partner[row['entity']], value['EntityCurrencyTotal'],
audittrail[
'REPORT'], movement['BAL'], *d_none_pov)
data1 = get_cell(pov1)
data2 = row['decimal_val']
if data2 - data1 > 0:
print('kkkkkkkkk')
row['decimal_val'] = data2 - data1
dc.con(row=row, dest=(entity[dc.cur_entity], partner['NoPartner'], account['220299'],
audittrail['INTERCO_ELIM'],
value["Elimination"]
), factor=-1, nature='关联往来抵销')
-
性能消耗:
-
按大抵
-
 - 常规抵销
-
- 常规抵销
-

考虑到存数取数的IO耗时,按大抵的逻辑实际计算耗时增加了一倍以上。
6.权益法调整规则
vPat = parse_parent(cur_entity)
## 清数
main_cube.clear_data(ad['EQADJ'])
## EQADJ期初结转, EQADJ=上年EQADJ_T
if cur_year > '2018':
# 4103= 不结转期初
# 410411 = 上年4104+410301
main_cube.loc[(ac['410411'], *movementope_eqadj)] = \
fn.round(main_cube.loc[(ac['4104'], *just_last_year_period, value_pa, *movementgen_eqadj_t)] + \
main_cube.loc[(ac['410301'], *just_last_year_period, value_pa, *movementgen_eqadj_t)], 2)
# 4104(除410411)= 不结转期初
# 其他科目=上年
account_bs_base_remove_410301_4104base = ac['BS'].Base() - ac['410301'] - ac['4104'].Base()
main_cube.loc[(account_bs_base_remove_410301_4104base, *movementope_eqadj)] = \
fn.round(main_cube.loc[(*just_last_year_period, value_pa, *movementgen_eqadj_t)], 2)
child = dc.EntityMD.list(vPat, 'child', with_parent=True)
## 这里返回的 子公司清单中已经排除掉active是否的了,所以不用判断 isactive
for ch in child:
ch = ch.data # loc中直接使用ch(EntityStr类型)会报错,需要使用 ch.data(string类型)
ch_only_child = parse_child(ch) # 获取fu.zi 中的 纯zi
is_subsid = dc.EntityMD.entity_type(ch) == 'subsidiary'
vPown = dc.EntityMD.share_percentage(ch) # 持股比例
if is_subsid and vPown > 0:
accts1 = \
ac['4301'].Base() + \
ac['4401'].Base() + \
(ac['4002'].Base() - ac['400201'])
movements = mov['INC', 'DEC', 'EXADJ', 'OPEE1']
# par[ch_only_child] partner不可以传fu.zi
main_cube.loc[(accts1, par[ch_only_child], *d13_GEN, ad['EQADJ'], movements)] = \
fn.round(main_cube.loc[en[ch], val['CNYTotal'], par['TotalPartner'], ad['Report']] * vPown, 2)
if cur_year > '2018':
target_audEQADJ_d13GEN = (par[ch_only_child], *d13_GEN, ad['EQADJ'])
# 定义目标1来源+目标2的7、8来源
source_movOPEE1 = (
en[ch], *d13_GEN, mov['OPEE1'], ad['Report'], val['CNYTotal'], par['TotalPartner'])
source_movNETMOV = (
en[ch], *d13_GEN, *movement_netmov_report, val['CNYTotal'], par['TotalPartner'])
main_cube.loc[(ac['410499'], *target_audEQADJ_d13GEN, mov['OPEE1'])] = \
fn.round((main_cube.loc[(ac['4104'], *source_movOPEE1)] +
main_cube.loc[(ac['4101'], *source_movOPEE1)]) * vPown, 2)
# 关于entity的处理
main_cube.loc[(ac['410499'], *target_audEQADJ_d13GEN, mov['INC'])] = \
fn.round((main_cube.loc[(ac['4104'], *source_movNETMOV)] +
main_cube.loc[(ac['4101'], *source_movNETMOV)] +
main_cube.loc[(ac['4102'], *source_movNETMOV)] -
main_cube.loc[(ac['410406'], *source_movNETMOV)] -
main_cube.loc[(ac['410412'], *source_movNETMOV)] -
main_cube.loc[(ac['410407'], *source_movNETMOV)] -
main_cube.loc[(ac['4104'], *source_movOPEE1)] -
main_cube.loc[(ac['4101'], *source_movOPEE1)]) * vPown, 2)
# Retained Earning mov
target_movGEN_audEQADJ = (par[ch_only_child], *d13_GEN, *movementgen_eqadj)
source_value_CNYTotal = (en[ch], *d13_GEN, mov['MovementGEN'], val['CNYTotal'], par['TotalPartner'])
source_value_PA = (en[ch], *d13_GEN, mov['MovementGEN'], val['ParentAdjs'], par['TotalPartner'])
main_cube.loc[(ac['61110198'], *target_movGEN_audEQADJ)] = \
fn.round((main_cube.loc[(ac['4103'], *source_value_CNYTotal, ad['Report'])] +
main_cube.loc[
(ac['PL60000000'], *source_value_PA, ad['PGZZADJ_T'])]) * vPown, 2)
main_cube.loc[(ac['61110101'], *target_movGEN_audEQADJ)] = \
fn.round(main_cube.loc[ac['410406'], en[ch], ad['Report'],
mov['NETMOV'], val['CNYTotal'], par['TotalPartner']] * vPown, 2)
main_cube.loc[(ac['410301'], par[ch_only_child], *movementgen_eqadj)] = \
fn.round(main_cube.loc[ac['PL60000000']], 2)
main_cube.loc[(ac['410301'], par[ch_only_child], mov['INC'], ad['EQADJ'])] = \
fn.round(main_cube.loc[ac['PL60000000'], mov['MovementGEN']], 2)
target_audEQADJ_d3GEN = (par[ch_only_child], d3['D3GEN'], ad['EQADJ'])
main_cube.loc[(ac['15110102'], *target_audEQADJ_d3GEN, mov['INC'])] = \
fn.round(main_cube.loc[ac['BS41000000'], mov['INC']] - \
main_cube.loc[ac['BS41000000'], mov['DEC']] + \
main_cube.loc[ac['BS41000000'], mov['EXADJ']], 2)
main_cube.loc[(ac['15110102'], *target_audEQADJ_d3GEN, mov['OPEE1'])] = \
fn.round(main_cube.loc[ac['BS41000000']], 2)
7.权益法抵销规则
## Equity Elimination-子公司权益抵消
account_BS41000000_desc = (ac['BS41000000'].Base() - ac['410301']).attr('name').collect()
if vMethon == 'equ_consol' and entity_type == 'subsidiary' and ElimEquity:
df = df_equity[
(df_equity['account'].isin(account_BS41000000_desc))
]
if not df.empty:
dc.con(row=df, dest=(value_elim, ad['EQElim']), factor=-1, nature='权益抵消')
dc.con(row=df, dest=(ac['PLUG03'], value_elim, par['NoPartner'], ad['EQElim']), factor=1,
nature='权益抵消')
9.重置流程控制计算状态
回到顶部
咨询热线
400-821-9199
