维度数据集成
本文说明如何通过数据流节点和 DeepModel 对象向维度同步成员数据,适用于需要从外部系统或平台其他模块批量写入维度成员的场景。
通过数据流提交维度数据
数据流是平台内置的数据处理管道,适合从 ERP、HR 等外部系统定期同步维度成员,或在平台内跨模块流转数据。
配置数据流节点时,需要将目标维度元素指定为写入对象,并按维度成员属性的字段映射规则配置好各列。
成员重排序:数据流节点提供”成员重排序”选项,开启后系统会在提交前自动将数据按先父后子的顺序重新排列。该功能可避免因子节点先于父节点写入而导致的”找不到父节点”错误。数据量较大时排序操作会影响性能,建议仅在数据源无法保证父子顺序时开启。
可参考数据流相关节点文档 https://docs.deepfos.com/component/deeppipeline/nodes/components/dimension
通过 DeepModel 同步维度数据
当维度元素以 DeepModel 对象为基础创建时,成员数据在 DeepModel 对象侧管理,维度侧通过 同步 操作拉取最新数据。用于进行业务侧的主数据和管理分析使用的维度的一致性管理。
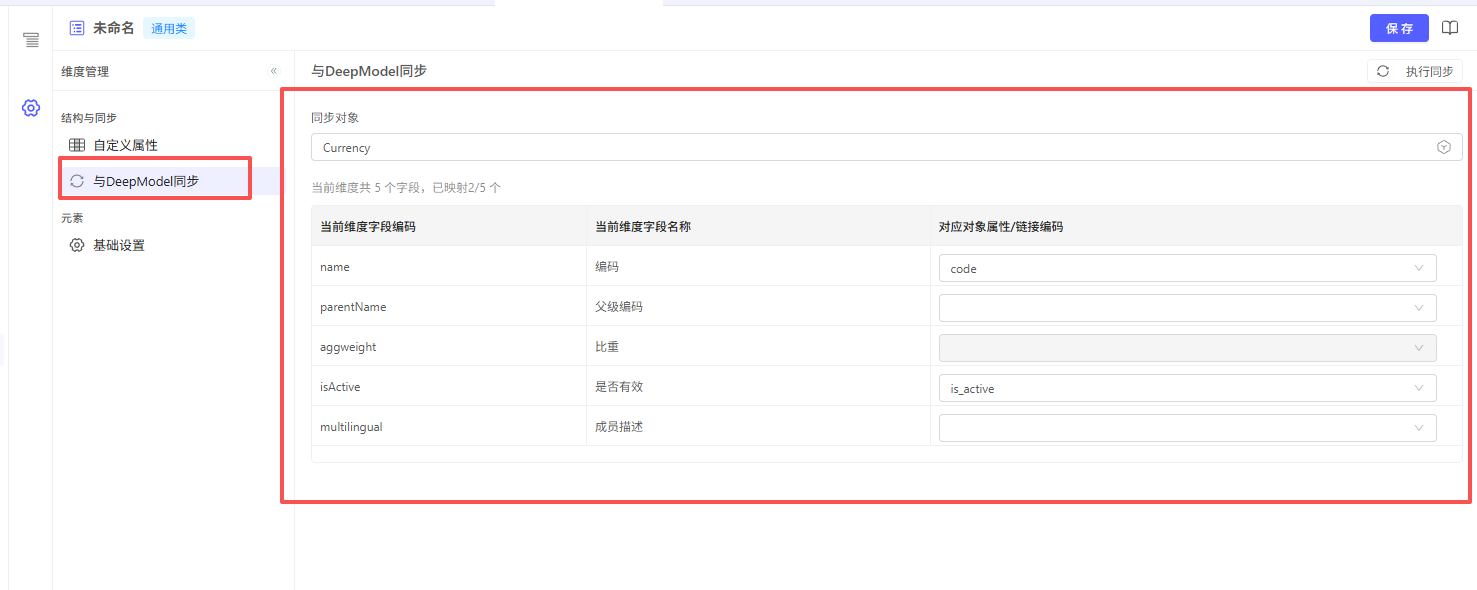
新建维度时,部分维度类型支持选择 从DeepModel同步

点击左侧 设置 按钮,在 与DeepModel同步 面板中,选择要同步的对象,并配置映射字段。点击开始数据同步。
-
这类维度在界面上无法直接编辑成员,所有成员的新增、修改、删除都在 DeepModel 对象侧完成。
-
可以手动触发同步,也可以通过数据流节点自动触发。目前无法在对象侧修改时自动触发。
-
同步完成后,维度成员会更新为对象侧的最新状态。
-
通过这种简易途径进行的同步,必须是全量一致的,如果需要更新部分成员,则可以通过数据流或py进行集成。
通过Python同步维度数据
要进行一些复杂逻辑操作以及默认同步逻辑不支持的维度类型时,适合通过python来进行集成。系统提供了对应的Py sdk。 https://py.deepfos.com/quick_start/element_dimension.html
同步示例可参考下文。
"""
@author: sicong
@timestamp: 2024/11/8
模块:组织架构
逻辑:组织从对象到维度全量同步
"""
from deepfos.element.dimension import Dimension
from deepfos.element.deepmodel import DeepModel
from .config import entity_name, entity_path
def main(p1, p2):
dm = DeepModel()
df_parent = dm.query_df(
"""
with
obj :=
(select
MA_Organization {
org_id,
parent
}
)
for item in (
org_id := obj.org_id,
parent_code := obj.parent.org_id,
parent_agg := obj.parent@aggweight
)
union
(select
{
name := item.org_id,
parent_name := item.parent_code,
aggweight := item.parent_agg
}
);
"""
)
df_entity = dm.query_df(
"""
select MA_Organization
{
name := .org_id,
language_zh_cn := json_get(.org_name, 'zh-cn'),
language_en := json_get(.org_name, 'en'),
ud1 := .org_type.org_type_id,
ud2 := .structure_type.structure_id,
local_currency := .base_currency.code,
}
"""
)
df_entity['language_zh_cn'] = df_entity['language_zh_cn'].str.strip('"')
df_entity['language_en'] = df_entity['language_en'].str.strip('"')
df_parent['sharedmember'] = df_parent['name'].duplicated()
df_entity = df_entity.merge(df_parent, on='name', how='left')
df_entity['parent_name'].fillna('#root', inplace=True)
df_entity['aggweight'] = df_entity['aggweight'].astype('float64')
df_entity['aggweight'].fillna('1', inplace=True)
df_entity['sharedmember'].fillna(False, inplace=True)
df_entity.sort_values(by='name', inplace=True)
entity = Dimension(entity_name, path=entity_path)
entity.load_dataframe(df_entity, strategy='full_replace', language_zh_cn='language_zh_cn')
回到顶部
咨询热线
400-821-9199
