常用计算
以下列出常用计算的DeepQL查询语句,包括相关语法、函数的介绍
属性类型
DeepModel各属性类型对应DeepQL数据类型、值例子。注:< type > anytype表示强制类型转换
|
DeepModel属性类型 |
DeepQL数据类型 |
值例子 |
|---|---|---|
|
文本 |
str |
‘REQ_202306_3’ |
|
多语言文本 |
json |
to_json(‘{“en”: “DeepModel”, “zh-cn”: “DeepModel”}’) |
|
布尔值 |
bool |
true/false |
|
整数 |
int64 |
123 |
|
小数 |
decimal |
1.23 |
|
日期时间 |
cal::local_datetime |
<cal::local_datetime>’2023-10-01 12:00:00’ |
|
枚举值 |
str |
‘approved’ |
|
文件 |
json | |
|
UUID |
uuid |
<uuid>’ea5fd52e-666f-11ee-9f32-db6d929ef47d’ |
比较操作符
类似其他查询语言如下
-
anytype = anytype:等于
-
anytype != anytype:不等于
-
anytype ?= anytype:等于(可对比空值)
-
anytype ?!= anytype:不等于(可对比空值)
-
anytype < anytype:小于
-
anytype > anytype:大于
-
anytype <= anytype:小于等于
-
anytype >= anytype:大于等于
注:等于/不等于使用=/!=时,无法对比空值,即操作符两边任一操作数为空时对比结果为空集;使用?=/?!=时可以对比
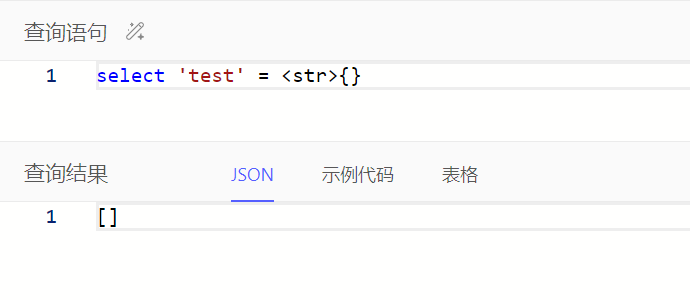
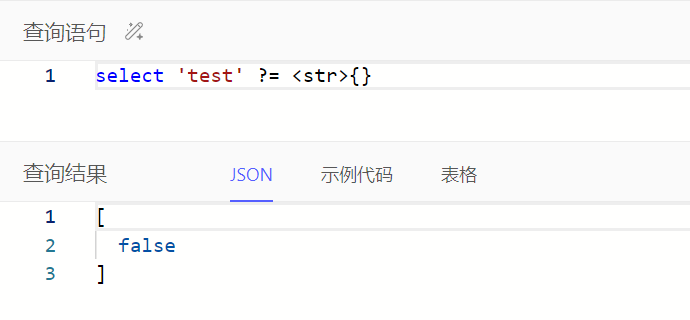
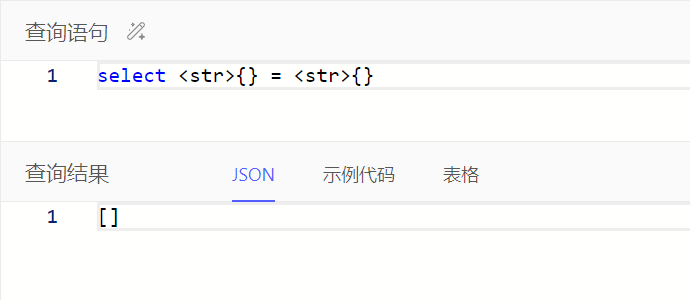
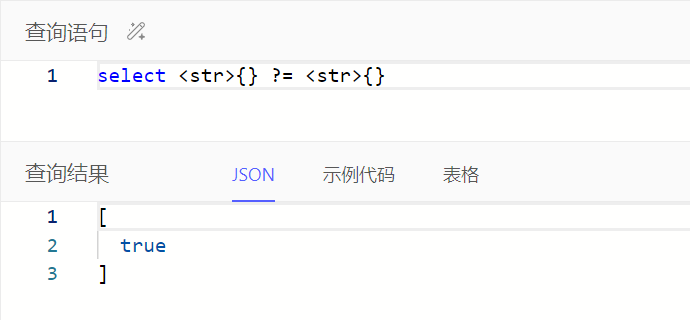
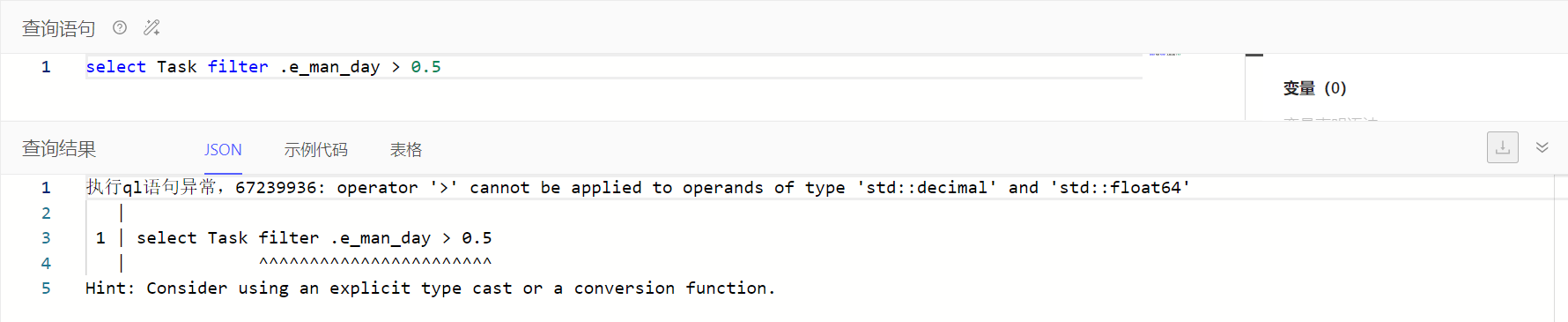
小数属性在比较时,可能需要强转其他小数对比值类型为decimal,具体按报错信息调整查询语句即可。如下例子可调整查询语句为select Task filter .e_man_day > <decimal>0.5
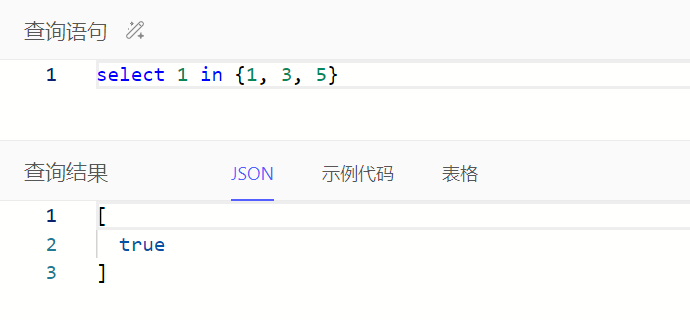
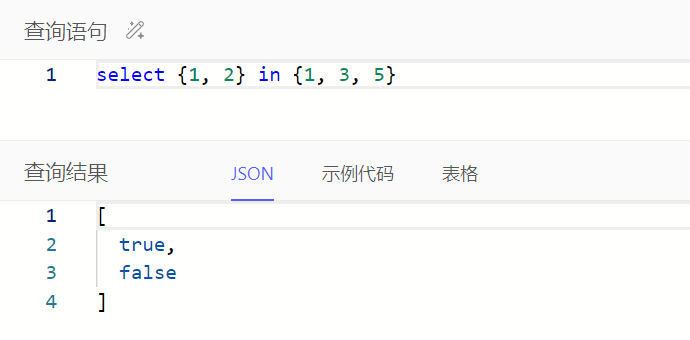
在…列表中、不为空
通过in、not in判断左操作数中每个元素是否在右操作数中
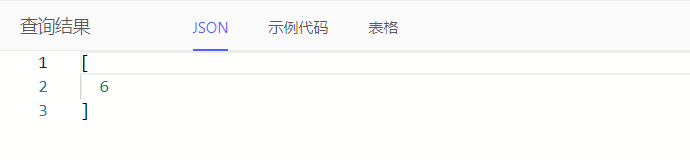
例如:统计开发+测试任务总数
select count(Task filter .task_type in {'dev', 'test'})
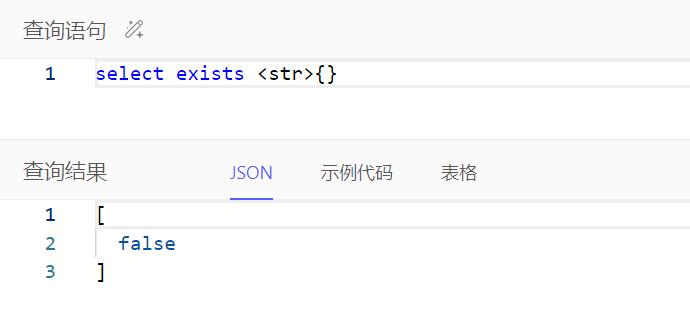
通过exists、not exists判断集合是否不为空
文本相关
DeepQL查询语言中文本包含两类:regular、raw,通常使用regular
-
regular语法如:’a string’、”a string”
-
raw与regular区别在于不识别\,例如

常用文本相关语法、函数如下
-
str ++ str:文本拼接
-
str like pattern、str not like pattern:大小写敏感的文本匹配
-
str ilike pattern、str not ilike pattern:大小写不敏感的文本匹配
-
to_str(val: int64/decimal/cal::local_datetime, fmt: optional str={}):输入值转为文本 -
len(value: str):文本长度 -
contains(haystack: str, needle: str):字符串是否包含子字符串 -
str_lower(string: str):输入文本转为小写 -
str_upper(string: str):输入文本转为大写 -
str_trim(string: str, trim: str = ' '):输入文本去掉首尾指定字符,不指定时默认去掉首尾空格 -
str_replace(s: str, old: str, new: str):将输入文本中所有老字符串替换为新字符串 -
str_split(s: str, delimiter: str):通过分隔符将输入文本转为文本数组
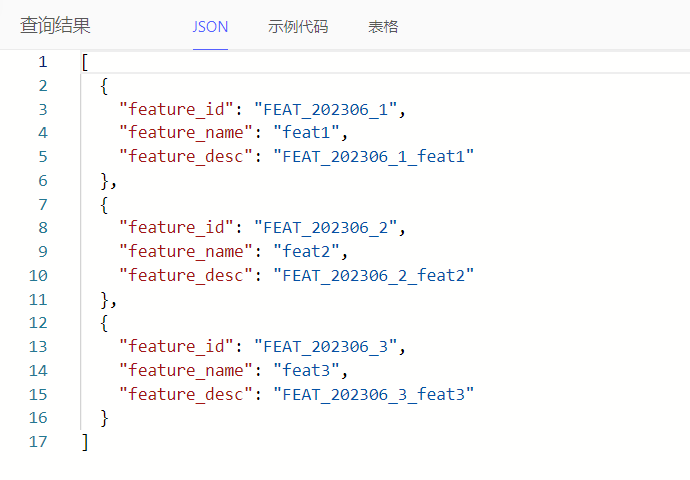
文本拼接例子
使用下划线_拼接功能的ID、名称,作为功能的描述
select Feature {
feature_id,
feature_name,
feature_desc := .feature_id ++ '_' ++ .feature_name
}
文本匹配规则

文本转对象
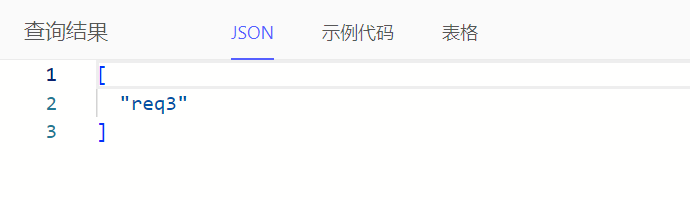
为方便获取对象数据,支持通过<${对象编码}>'${对象业务主键值}'将文本值转为对象数据
可通过文本转对象获取指定对象数据的属性/链接值。例如:查询指定需求的需求名称
select (<Requirement>'REQ_202306_3').req_name
多语言文本中指定语言值
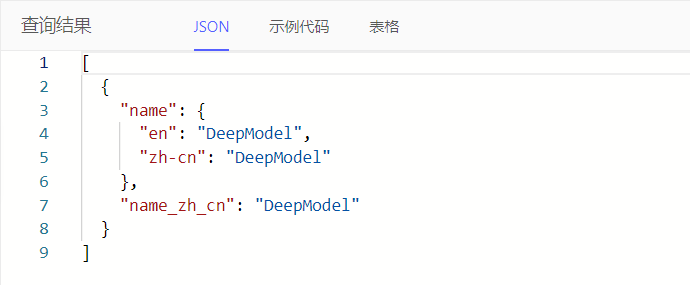
通过json_get()获取JSON中指定键对应值,常用于多语言文本中指定语言值,由于DeepModel中多语言文本底层JSON类型存储,key表示当前空间各种语言。例如:查询组件的名称(多语言文本)、中文名称
注:由于json_get()返回值类型为json,建议强转类型为str即文本
select Component {
name,
name_zh_cn := <str>json_get(.name, 'zh-cn')
}
布尔表达式
类似其他查询语言如下
-
bool or bool:两个布尔值中任一值为true,则为true
-
bool and bool:两个布尔值都为true,则为true
-
not bool:指定布尔值的非值
-
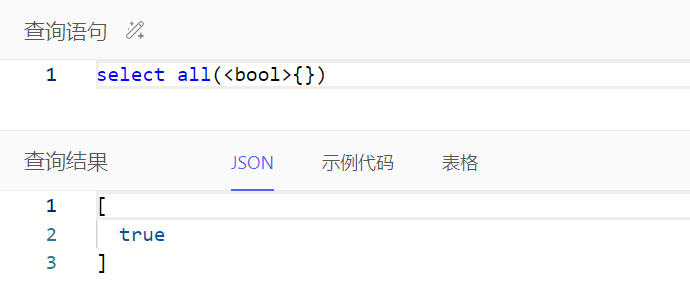
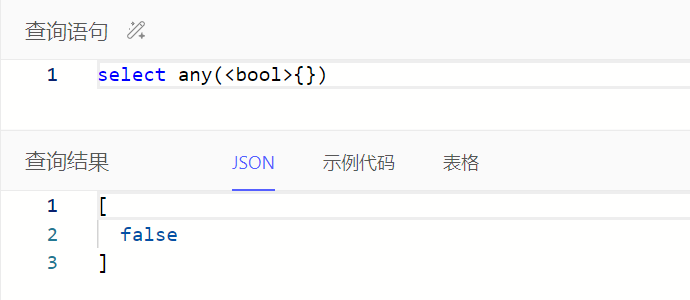
all():如果集合中没有一个值为false,则为true
-
any():如果集合中任一值为true,则为true
-
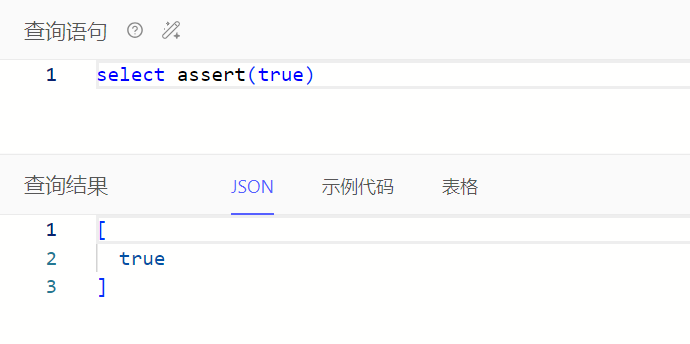
assert():校验输入布尔值是否为true
注:or、and、not表达式中任一操作数为空时查询结果为空集,可通过操作符??确保查询结果为布尔值,语法如:A ?? B,表示A非空则为A,否则为B
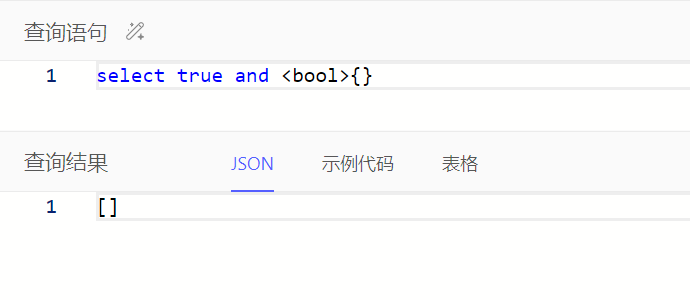
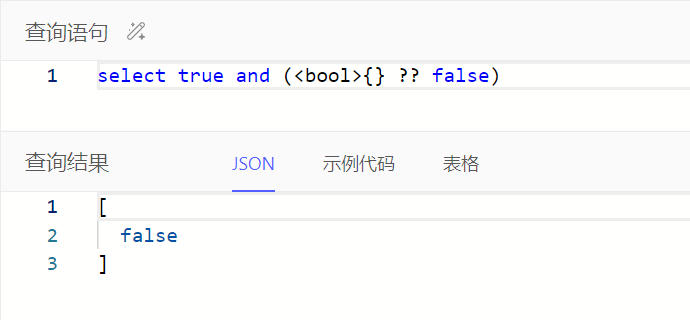
all()、any()输入为空时查询结果为布尔值
assert()可用于校验输入布尔值是否为true,如果为true,则返回true,否则报错,支持自定义报错信息
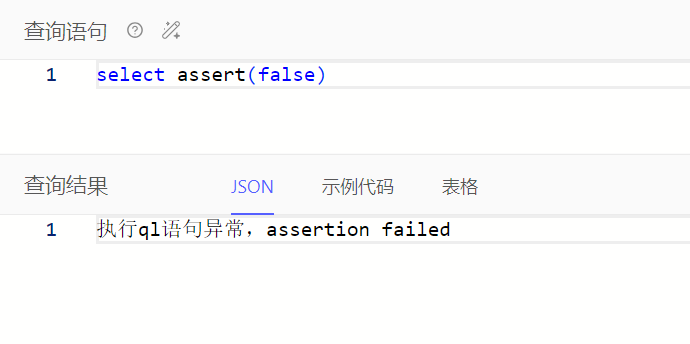
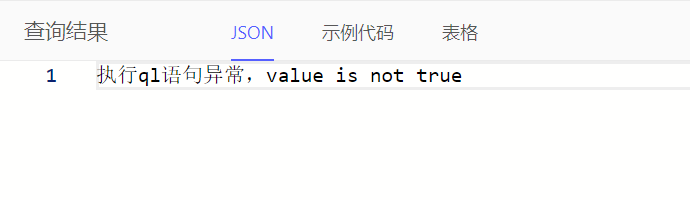
select assert(false, message := 'value is not true')
计数/去重计数
通过count()对集合进行计数。例如:统计任务总数
select count(Task)
在头表获取关联的行表数据进行计数,例如:查询每个功能的关联任务数量、开发任务数量
select Feature {
feature_id,
feature_name,
task_count := count(.<feature[is Task]),
dev_task_count := count(.<feature[is Task] filter .task_type = 'dev')
}

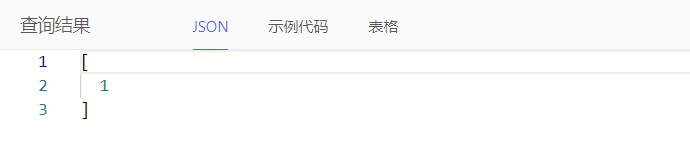
通过count(distinct)对集合进行去重计数。例如:统计任务状态去重总数
select count(distinct Task.task_status)
在头表获取关联的行表数据进行去重计数,例如:查询每个功能的关联任务状态去重数量、开发任务状态去重数量
select Feature {
feature_id,
feature_name,
tsk_stat_d_count := count(distinct .<feature[is Task].task_status),
dev_tsk_stat_d_count := count(distinct (select .<feature[is Task] filter .task_type = 'dev').task_status)
}

数字计算
支持常用的数字计算如下,注:由于DeepModel中整数、小数分别对应DeepQL的int64、decimal,计算属性DeepQL模式中可能需要强制类型转换类似:<int64>xxx、<decimal>xxx
-
anyreal + anyreal:加
-
anyreal - anyreal:减
-
- anyreal:负值
-
anyreal * anyreal:乘
-
anyreal / anyreal:除,除数不能为0
-
anyreal // anyreal:向下整除,除数不能为0
-
anyreal % anyreal:取模,除数不能为0
-
anyreal ^ anyreal:次幂
-
sum(s: set of int64/decimal):求和 -
min(values: set of anytype):最小值 -
max(values: set of anytype):最大值 -
round(value: int64/decimal):四舍五入 -
random():[0.0, 1.0)的伪随机数 -
math::abs(x: anyreal):绝对值 -
math::ceil(x: int64/decimal):向上取整 -
math::floor(x: int64/decimal):向下取整 -
math::mean(vals: set of int64/decimal):平均值 -
math::percentile_cont(values: set of anyreal, fraction):计算数字集合排序后的连续百分位数(可插值),fraction即指定百分位,为0到1之间的小数,fraction = 0.5时表示计算中位数
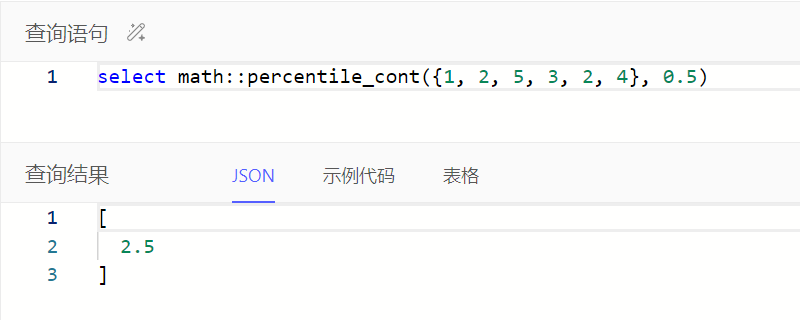
以sum()求和为例
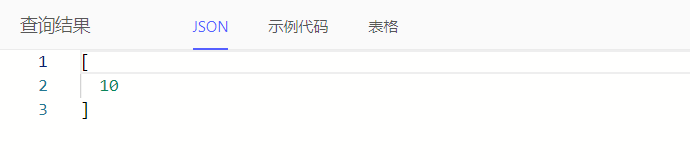
例如:统计任务预估总人天
select sum(Task.e_man_day)
在头表获取关联的行表数据进行求和,例如:查询每个功能的关联任务预估人天之和、开发任务预估人天之和、开发任务预估人天占比(即开发任务预估人天之和 / 关联任务预估人天之和)
# 定义查询:计算每个功能的关联任务预估人天之和、开发任务预估人天之和
with FeatInfo := (select Feature {
feature_id,
feature_name,
e_man_day := sum(.<feature[is Task].e_man_day),
dev_e_man_day := sum((select .<feature[is Task] filter .task_type = 'dev').e_man_day)
})
# 基于查询结果计算:开发任务预估人天占比 = 开发任务预估人天之和 / 关联任务预估人天之和
select FeatInfo {
feature_id,
feature_name,
e_man_day,
dev_e_man_day,
ratio := .dev_e_man_day / .e_man_day if .e_man_day != 0 else 0
}

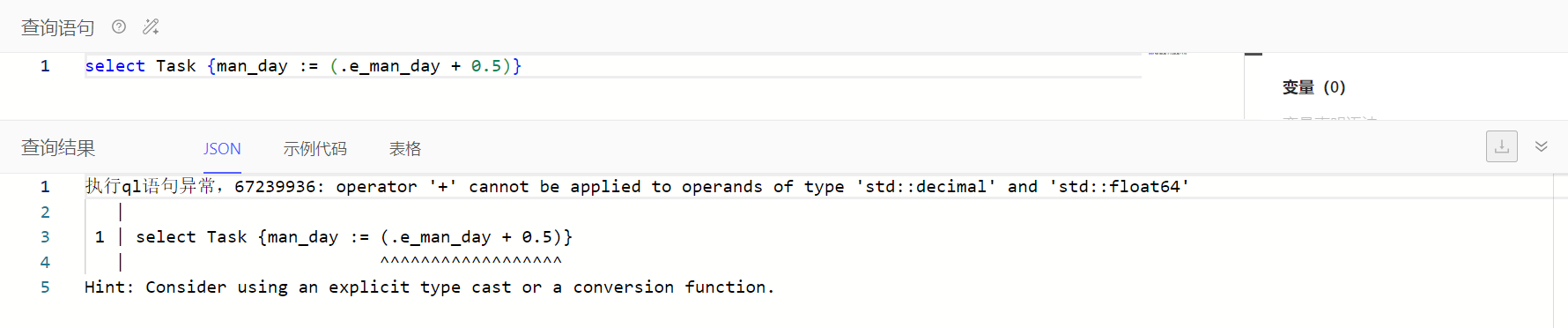
小数属性在计算时,可能需要强转其他小数计算值类型为decimal,具体按报错信息调整查询语句即可。如下例子可调整查询语句为select Task {man_day := (.e_man_day + <decimal>0.5)}
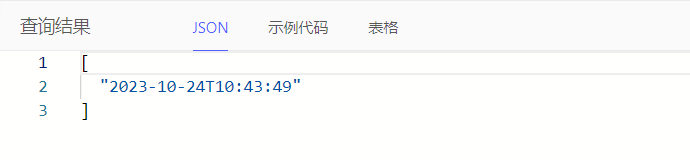
日期时间
通过cal::local_datetime_of_statement()获取当前时间
select cal::local_datetime_of_statement()
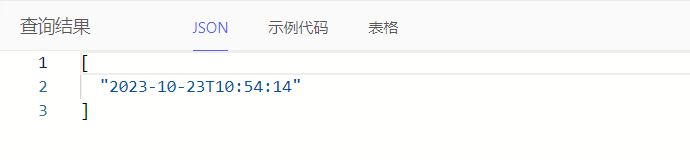
通过指定日期时间+/-cal::relative_duration得到所需的日期时间。例如:当前时间加减一天
select cal::local_datetime_of_statement() + <cal::relative_duration>'1 day'
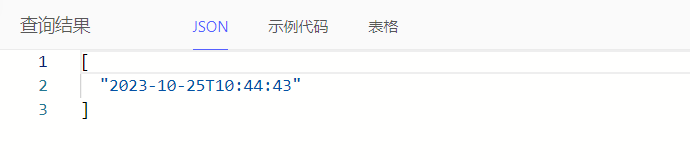
select cal::local_datetime_of_statement() - <cal::relative_duration>'1 day'
其中,可用时间单位包括:
-
‘microseconds’
-
‘milliseconds’
-
‘seconds’
-
‘minutes’
-
‘hours’
-
‘days’
-
‘weeks’
-
‘months’
-
‘years’
-
‘decades’
-
‘centuries’
-
‘millennia’
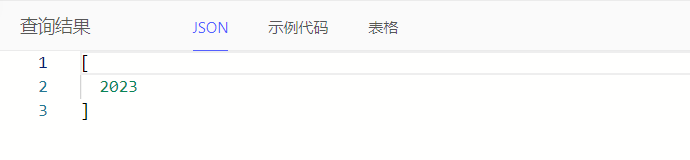
通过datetime_get()获取日期时间的年、月、日等部分
select datetime_get(<cal::local_datetime>'2023-10-01T00:00:00', 'year')
其中,可用时间单位包括:


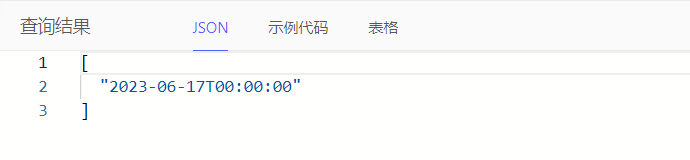
通过min()、max()获取日期时间的最小值、最大值。例如:统计任务最晚计划结束时间
select max(Task.p_end_date)
在头表获取关联的行表数据计算最小值、最大值,例如:查询每个功能的关联任务最晚计划结束时间、开发任务最晚计划结束时间
select Feature {
feature_id,
feature_name,
p_end_date := max(.<feature[is Task].p_end_date),
dev_p_end_date := max((select .<feature[is Task] filter .task_type = 'dev').p_end_date)
}

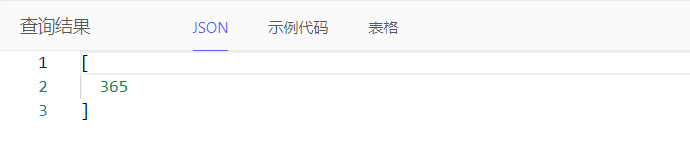
通过duration_get()获取两个日期时间之差的天部分作为两个日期时间相差天数
select duration_get(<cal::local_datetime>'2023-10-01T00:00:00' - <cal::local_datetime>'2022-10-01T00:00:00', 'day')
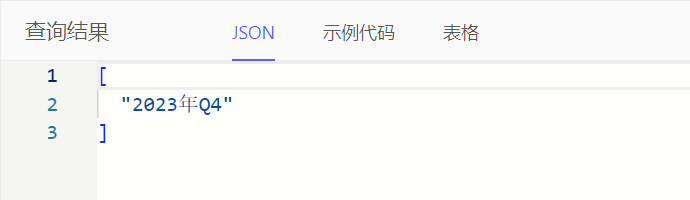
通过to_str()获取指定格式的日期时间文本
select to_str(<cal::local_datetime>'2023-10-01T00:00:00', 'YYYY-MM-DD')

select to_str(<cal::local_datetime>'2023-10-01T00:00:00', 'YYYY年MM月DD日')

select to_str(<cal::local_datetime>'2023-10-01T00:00:00', 'YYYY年"Q"Q')
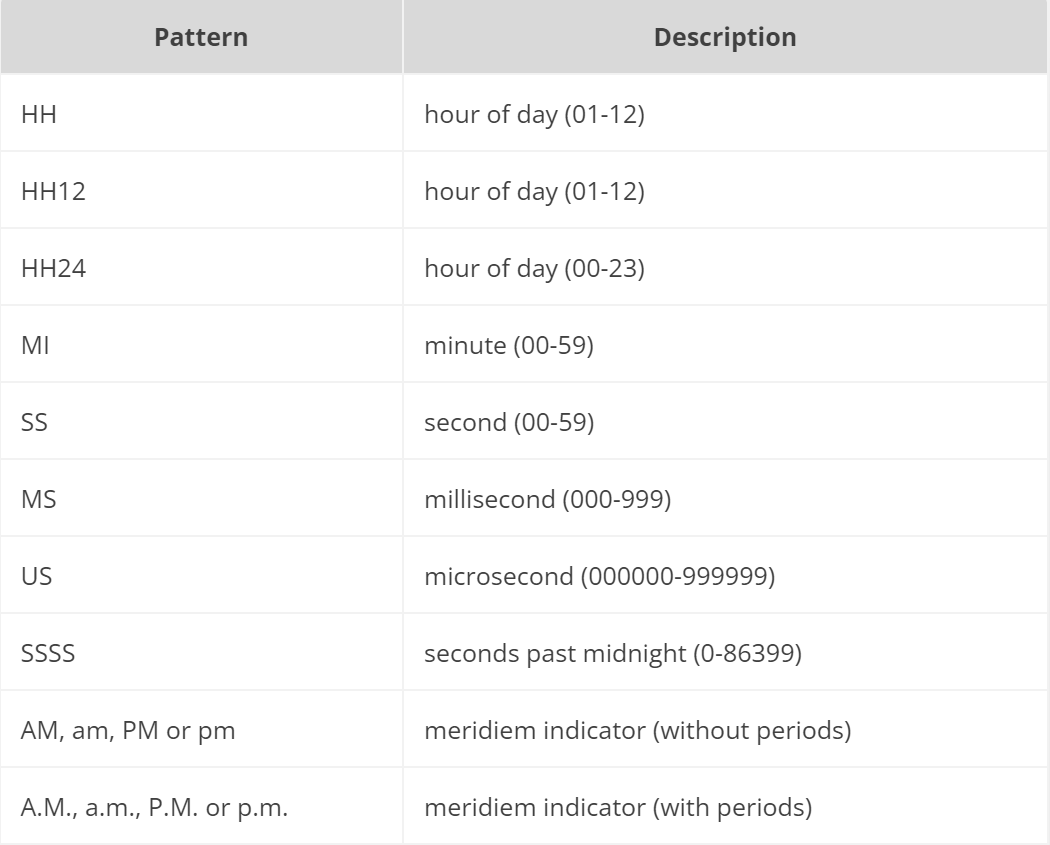
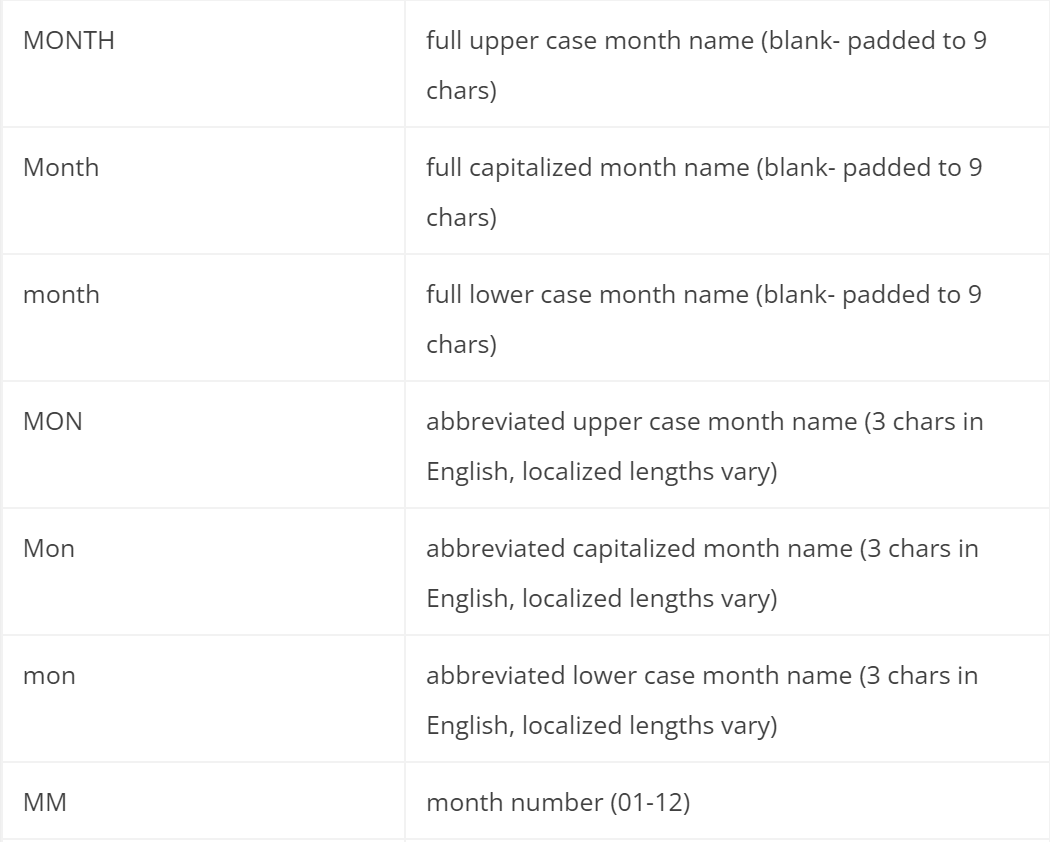
其中,可用时间格式包括:

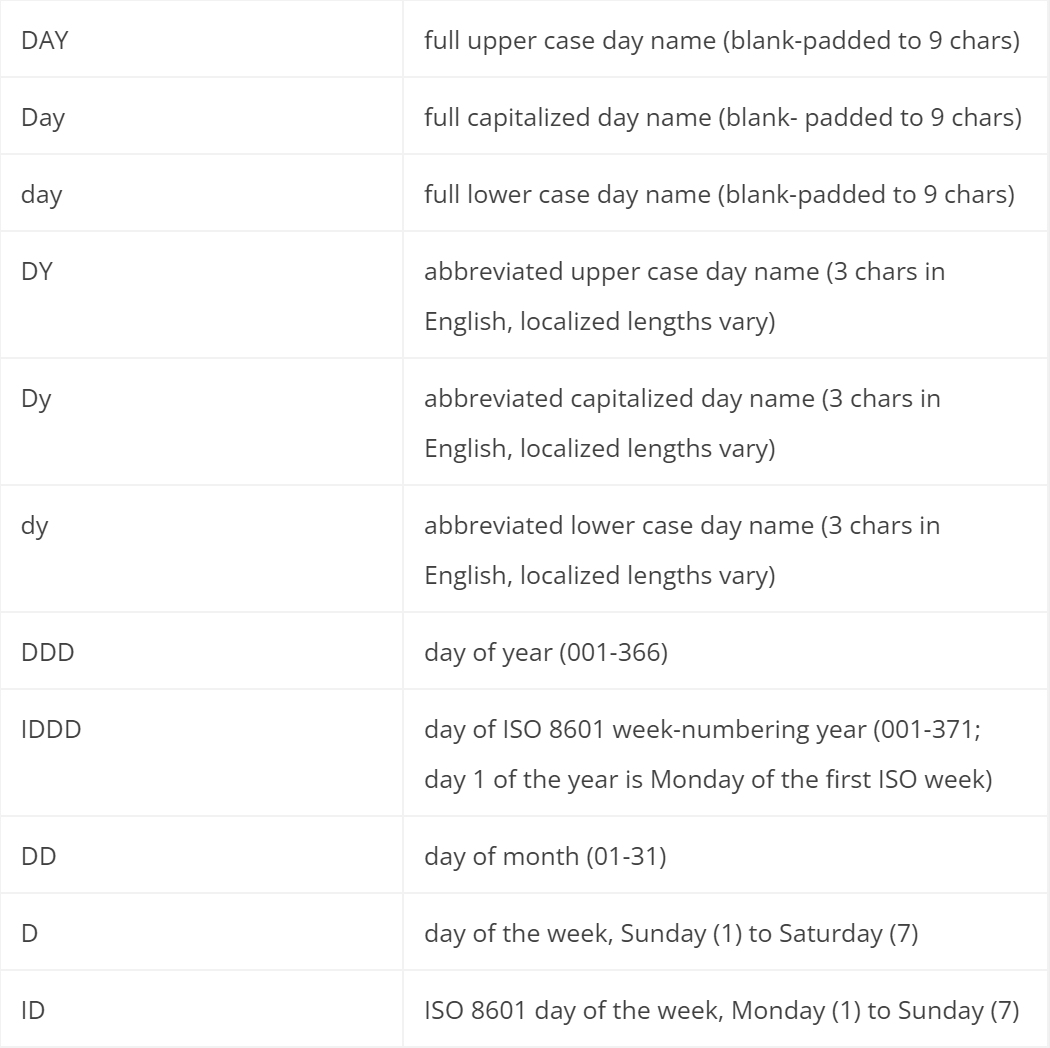
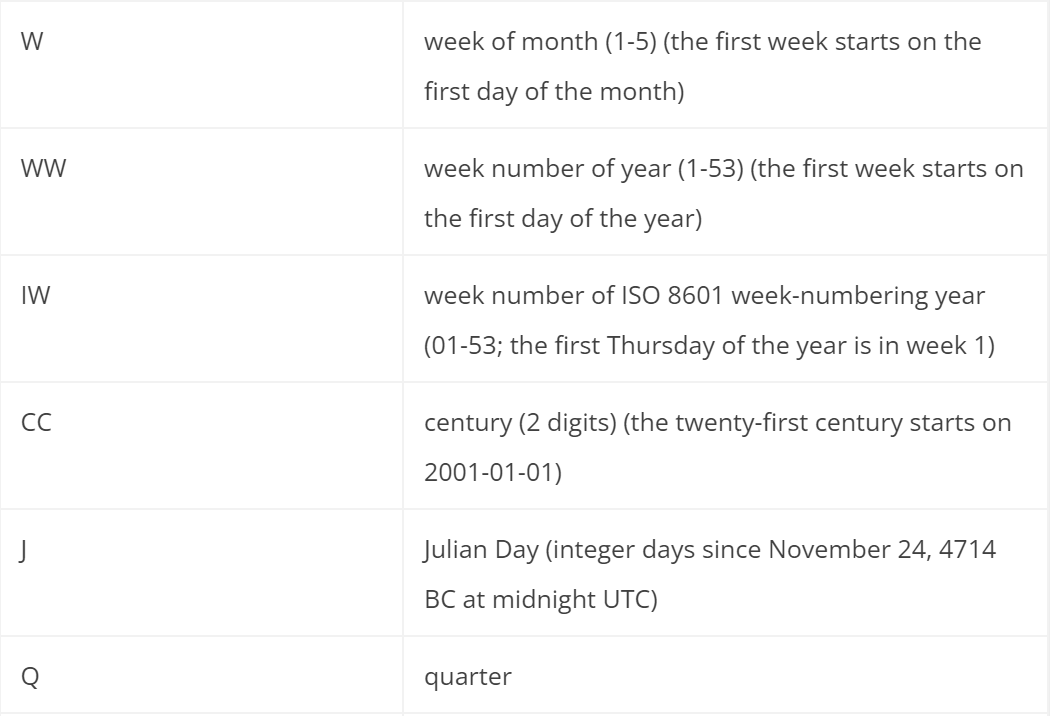
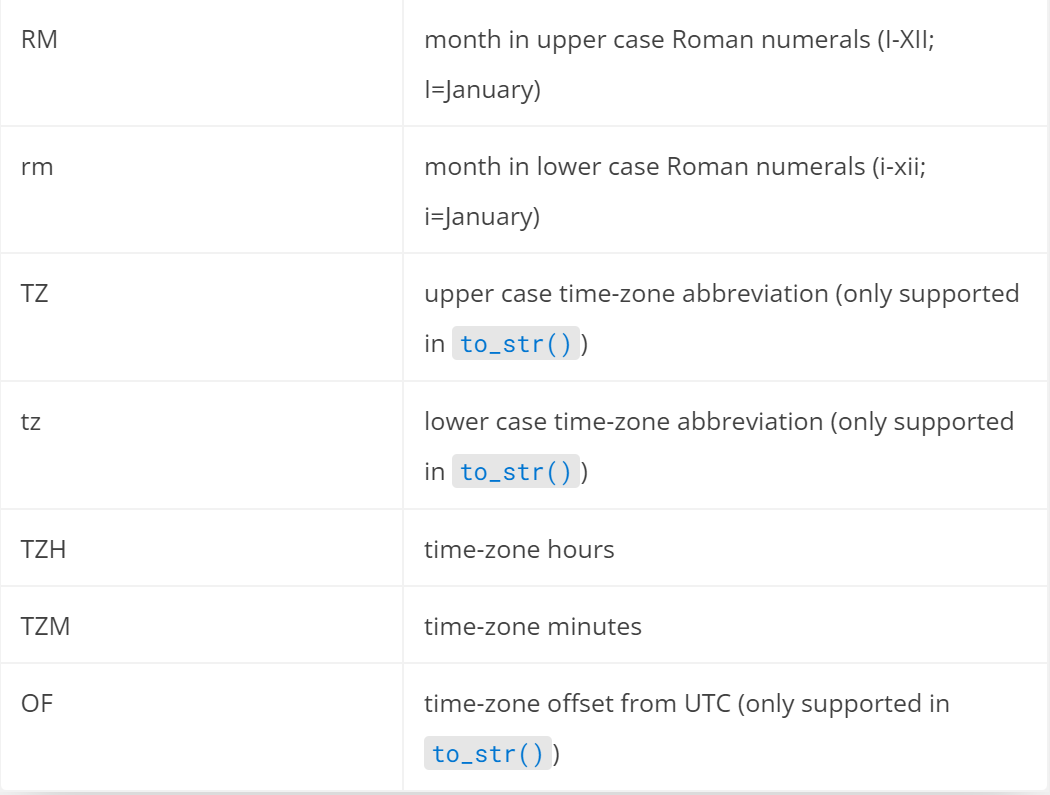
枚举值信息
DeepModel中枚举值底层str类型存储枚举值编码,目前提供获取枚举值信息的函数:dm::get_enum_info(module_name: str, object_name: str, enum_name: str, enum_prop: str = 'name') -> json
该函数包含四个参数
-
module_name:指定模块编码
-
object_name:指定对象编码
-
enum_name:指定枚举值属性编码
-
enum_prop:指定枚举值信息,默认为name即名称,目前枚举值信息主要包含名称
注:空间初始化时即预置枚举值信息函数,存量空间可通过重新注册DeepModel以新增该函数
可通过dm::get_enum_info()获取枚举值名称。例如:查询需求的需求状态(编码+中文名称)
with enum_mapping := dm::get_enum_info('appzauoyn184', 'Requirement', 'req_status')
select Requirement {
req_name,
req_status,
req_status_desc := <str>json_get(json_get(enum_mapping, .req_status), 'zh-cn')
}
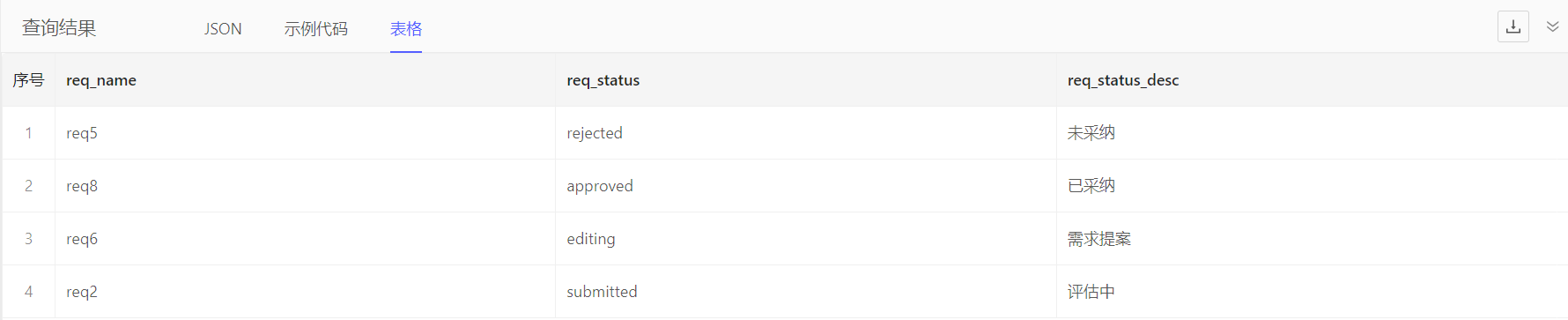
文件名
DeepModel中文件底层JSON类型存储,为数组即可能包含多个文件,每个文件信息同平台文件信息包括:id、url、fileName、fileSize、fileType、fileDescription、createUser,其中fileName表示文件名,可通过json_get()获取JSON中文件名对应值
注:由于json_get()返回值类型为json,建议强转类型为str即文本
select Requirement {
attachment,
file_name := <str>json_get(.attachment, 'fileName')
}
[
{
"attachment": [
{
"id": "U_25b50b4d-58a0-41fb-9276-cd9e15fc1533",
"url": "/opt/file//file/spacezauoyn/appzauoyn184/ATT/2024/01/ATT2024010317090713745.xlsx",
"fileName": "file1.xlsx",
"fileSize": 9952,
"fileType": "ATT",
"createUser": "62d7ea9f-cd92-4630-a173-37b18ef91fd0",
"fileDescription": "file1.xlsx"
}
],
"file_name": [
"file1.xlsx"
]
},
{
"attachment": [
{
"id": "U_682a8c20-bd97-46d3-baed-9e52e36b44ae",
"url": "/opt/file//file/spacezauoyn/appzauoyn184/ATT/2024/01/ATT2024010317100015329.xlsx",
"fileName": "file1.xlsx",
"fileSize": 9952,
"fileType": "ATT",
"createUser": "62d7ea9f-cd92-4630-a173-37b18ef91fd0",
"fileDescription": "file1.xlsx"
},
{
"id": "U_05363f16-800f-423e-b33a-54517e1dccc2",
"url": "/opt/file//file/spacezauoyn/appzauoyn184/ATT/2024/01/ATT2024010317103613183.xlsx",
"fileName": "file2.xlsx",
"fileSize": 9952,
"fileType": "ATT",
"createUser": "62d7ea9f-cd92-4630-a173-37b18ef91fd0",
"fileDescription": "file2.xlsx"
}
],
"file_name": [
"file1.xlsx",
"file2.xlsx"
]
}
]
if…else表达式、空值兼容
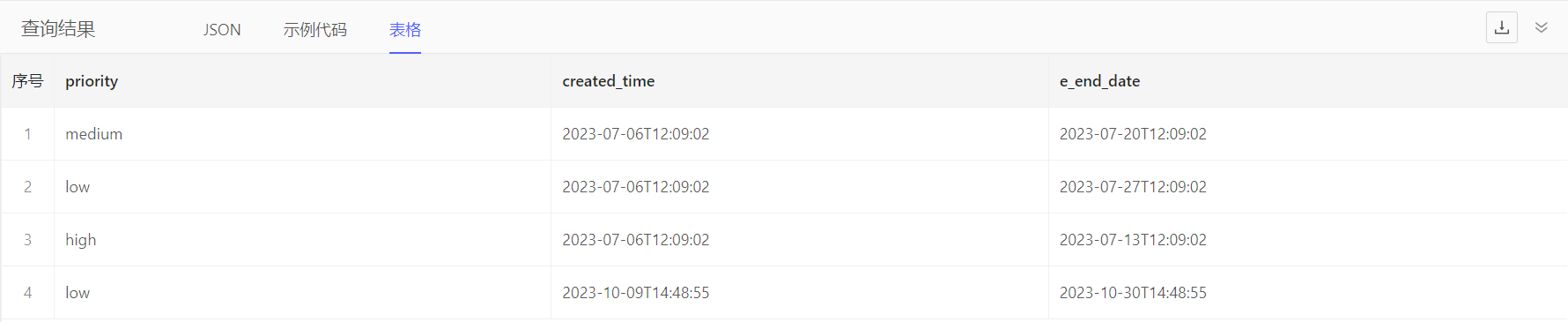
if…else表达式的语法如:左表达式 if 条件 else 右表达式,表示条件为true则取左表达式的值,条件为false则取右表达式的值。例如:按优先级计算需求的期望结束时间,优先级为高时,期望结束时间 = 需求创建时间 + 1周;优先级为中时,期望结束时间 = 需求创建时间 + 2周;优先级为低时,期望结束时间 = 需求创建时间 + 3周
select Requirement {
priority,
created_time,
e_end_date := .created_time + <cal::relative_duration>'1 week' if .priority = 'high' else
.created_time + <cal::relative_duration>'2 weeks' if .priority = 'medium' else
.created_time + <cal::relative_duration>'3 weeks' if .priority = 'low' else
.created_time + <cal::relative_duration>'3 weeks'
}
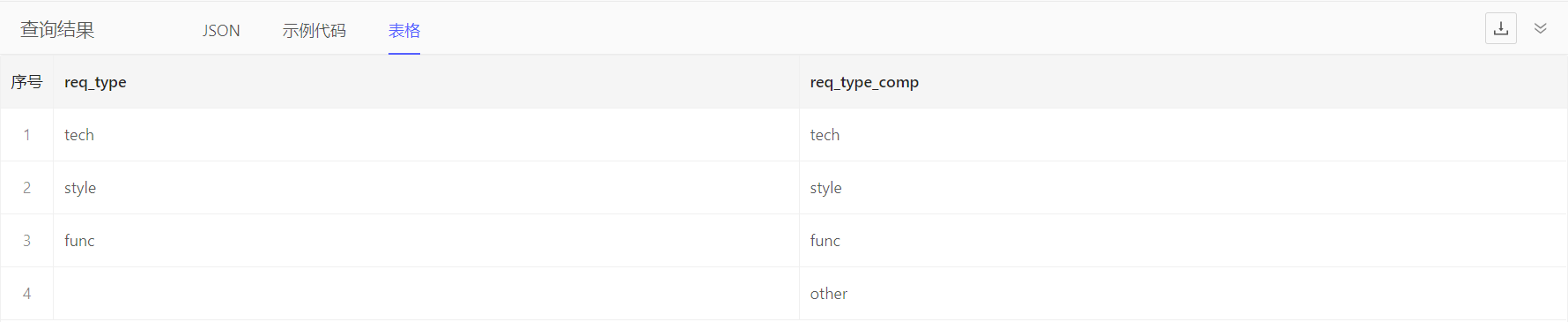
通过??进行空值兼容,语法如:A ?? B,表示A非空则为A,否则为B
select Requirement {
req_type,
req_type_comp := .req_type ?? 'other'
}
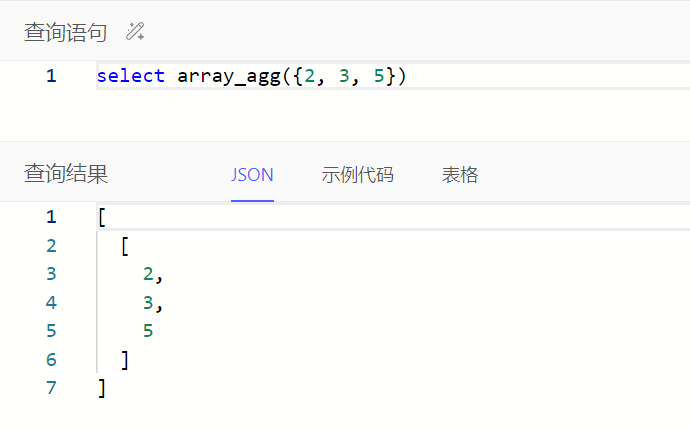
数组相关
通过array_agg()将输入集合转为数组
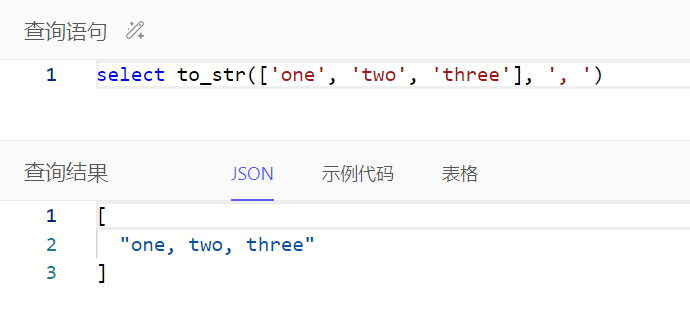
通过to_str()按指定字符拼接文本数组为文本
结合array_agg()、to_str()可按指定字符拼接文本集合为文本。在头表获取关联的行表数据拼接文本,例如:查询每个功能的关联任务名称,并使用、拼接作为功能的任务描述
select Feature {
feature_id,
feature_name,
task_desc := to_str(array_agg(.<feature[is Task].task_name), '、')
}

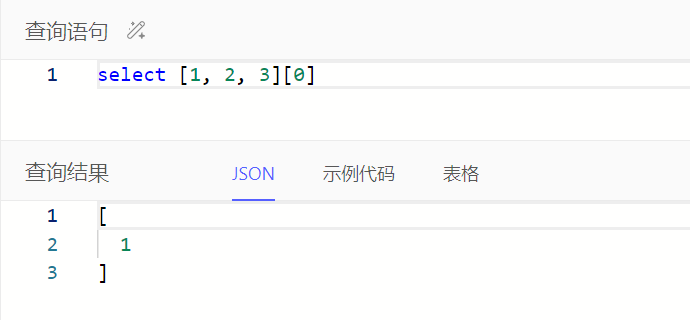
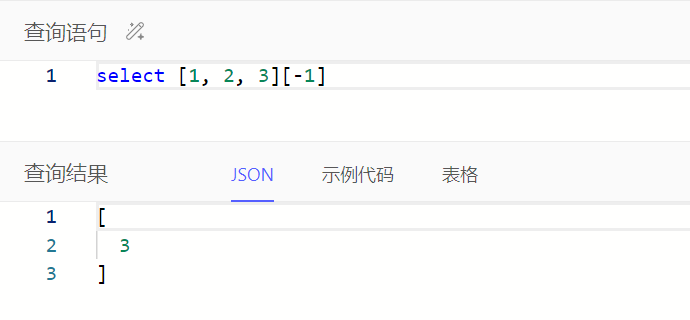
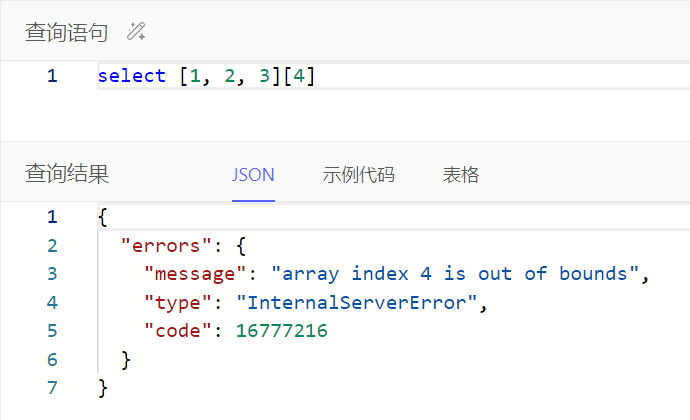
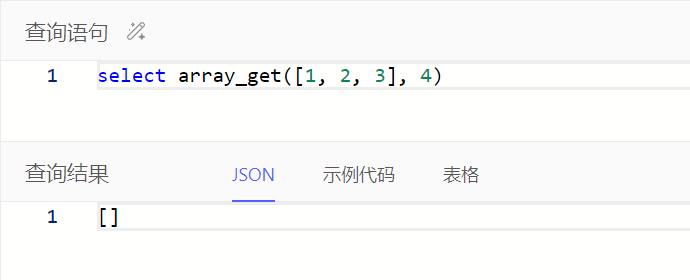
通过array[i]或array_get()获取数组中指定位置的值,区别在于指定位置超出数组范围时,array[i]会报错而array_get()会返回空集
其他聚合
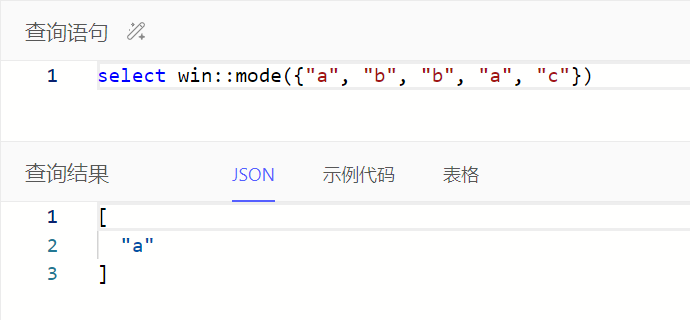
通过win::mode()获取集合中出现次数最多的值(如果有多个则随机选一个)
窗口函数
支持常用的窗口函数如下
-
win::row_number()
-
win::rank()
-
win::dense_rank()
-
win::percent_rank()
有以下三种写法
写法1:使用with区块定义窗口
# WITH win AS WINDOW (
# Object
# GROUP BY .link.prop, .prop
# ORDER BY .prop DESC THEN .link.prop
# )
# SELECT Object {
# w1 := sum(.prop) OVER win,
# w2 := math::mean(.prop) OVER win,
# w3 := win::rank() OVER win
# }
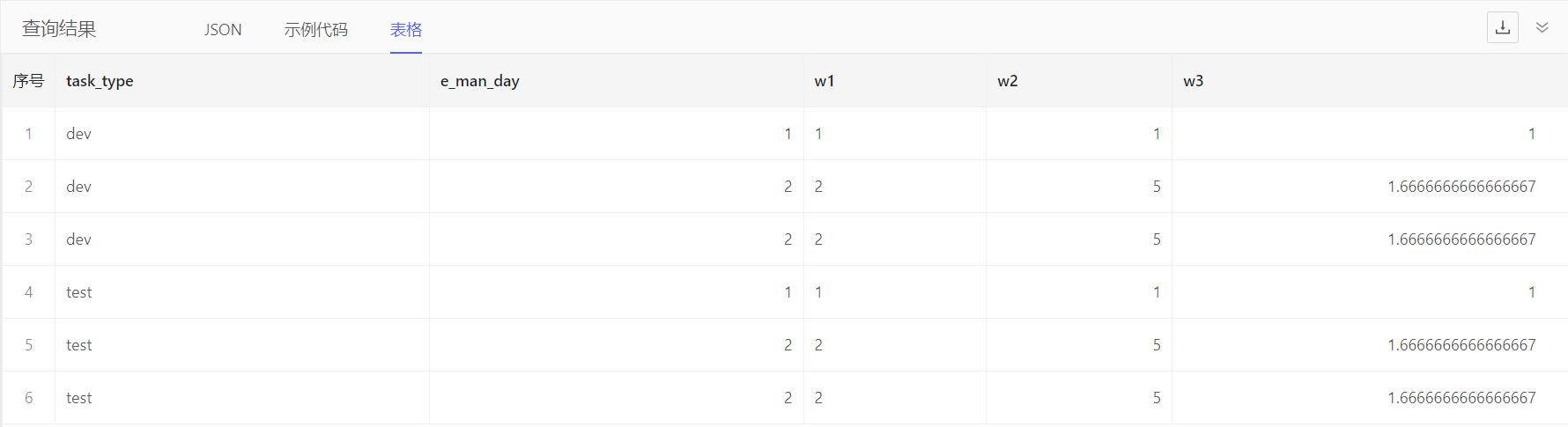
with win as window (
Task
group by .task_type
order by .e_man_day
)
select Task {
task_type,
e_man_day,
w1 := win::rank() over win,
w2 := sum(.e_man_day) over win,
w3 := math::mean(.e_man_day) over win
}
order by .task_type then .e_man_day
写法2:就地定义窗口
# SELECT Object {
# w1 := sum(.prop) OVER (GROUP BY .link.prop ORDER BY .prop DESC),
# w2 := math::mean(.prop) OVER (GROUP BY .link.prop ORDER BY .prop DESC)
# }
select Task {
task_type,
e_man_day,
w1 := win::rank() over (group by .task_type order by .e_man_day),
w2 := sum(.e_man_day) over (group by .task_type order by .e_man_day),
w3 := math::mean(.e_man_day) over (group by .task_type order by .e_man_day)
}
order by .task_type then .e_man_day
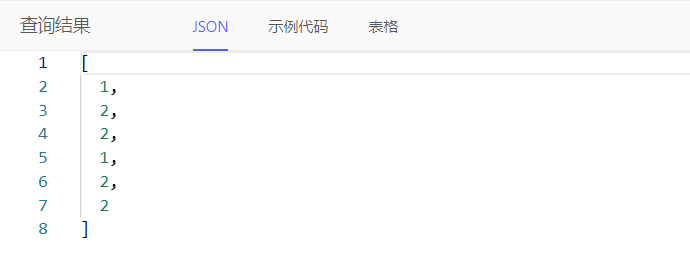
写法3:标量查询
# SELECT win::rank() OVER (Object GROUP BY .link.prop ORDER BY .prop DESC)
select win::rank() over (Task group by .task_type order by .e_man_day)
回到顶部
咨询热线
400-821-9199
