SQL语法建议
数据流中的【SQL转换】节点、【数据转换】节点的【列计算】步骤、【连接器查询】和【数据表查询】节点的SQL模式等,都会涉及到SQL语言的编写,因此有必要对SQL语言有一些基础认识。
不同数据库中的SQL语法各有不同,此文档仅以DuckDB数据库为例。
【连接器查询】和【数据表查询】节点的SQL语法需要符合该节点选择的数据库类型,其他未指定明确数据库的节点,都使用DuckDB数据库的SQL进行数据库处理(例如【SQL转换】节点、【数据转换】节点的【列计算】步骤)。
如何引用预置变量
如何在SQL框中引用数据流中的预置变量,详见预置变量章节:https://docs.deepfos.com/component/deeppipeline/function/variable#sql
如何确定DuckDB版本
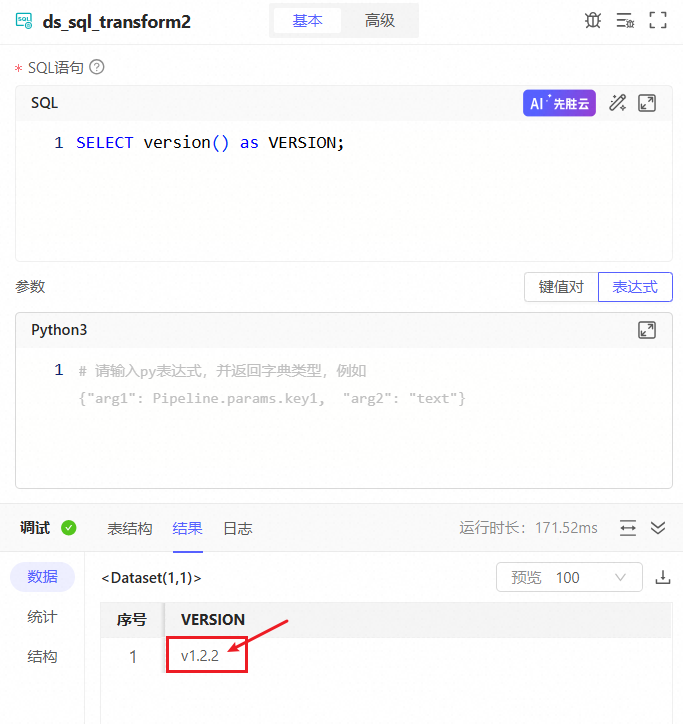
添加【SQL转换】节点,运行SELECT version()可得到版本信息。
借助AI工具
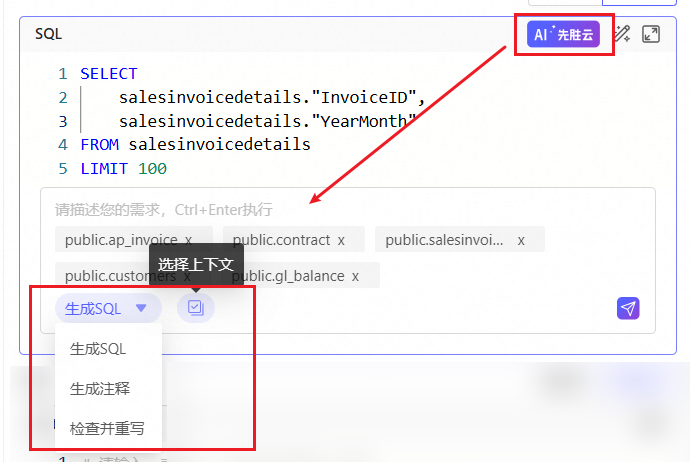
若您的环境部署了AI助手,在SQL框可直接使用AI助手来编写/分析/检查/重写SQL:
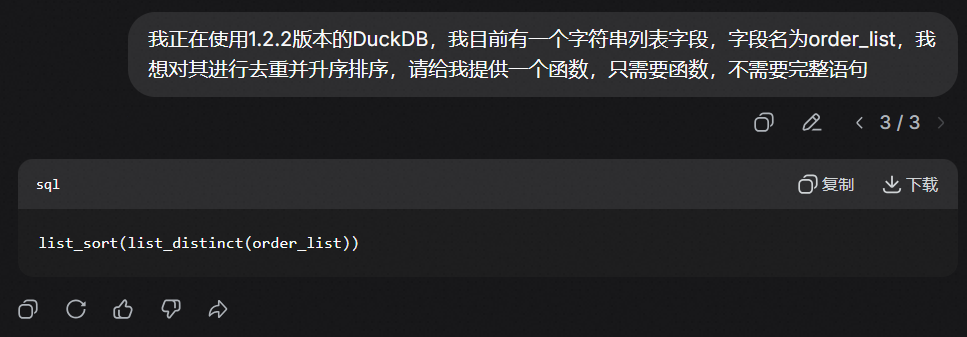
若未部署,也可自行使用AI工具进行查询,建议您在提示词中指明数据库类型和版本,以降低结果的错误率,以deepseek为例,其返回的list_sort(list_distinct(order_list))则是完全正确的语句。
常用函数
内部成员可访问语雀文档:https://proinnova.yuque.com/ys1krd/sa4wgw/tbze6ubagdvgs395
外部用户可进入SQL代码框的全屏状态,会在左侧展示常用函数的解释和示例。
以下表格是仅供参考的部分函数,下面表格后续不会进行更新,请至语雀文档或系统中查看最新的完整表格。
文本
因文档格式问题,用图片代替表格。

数值
|
示例 |
帮助说明 |
|---|---|
|
绝对值(abs) |
返回绝对值,用函数别名@也有同样效果。 |
|
四舍五入(round) |
四舍五入保留s位小数。允许s为负数。 |
|
行号(row_number) |
为每行生成一个行号,支持分区和区内排序。 |
日期
|
示例 |
帮助说明 |
|---|---|
|
提取(extract) |
提取日期字段中的年月日等组成部分,提取出的字段类型为整数。 |
|
格式化(strftime) |
将日期字段转换为指定格式的文本。常用的格式指定符号如下(注意大小写)。 |
|
今天(today) |
当前日期(本地时区),不带时分秒(时分秒都是0)。 |
|
月末(last_day) |
返回指定日期所在月份的最后一天,结合天数计算,还可以轻松得出月初的日期。 |
|
天数计算(+/-) |
用加减法进行日期间的天数计算。 |
时间
|
示例 |
帮助说明 |
|---|---|
|
现在(now) |
当前时间,数据流中会转化为0时区进行显示。以下函数效果相同:current_timestamp, get_current_timestamp(), transaction_timestamp()。 |
|
时间戳转换(to_timestamp) |
将自1970-01-01以来的秒数转换为0时区的时间,若是毫秒数,需要先除以1000,或使用epoch_ms函数,该函数可用于毫秒和本地时间的互相转换。 |
|
指定时区(AT TIME ZONE) |
返回指定时区的时间戳。 |
空值相关
|
示例 |
帮助说明 |
|---|---|
|
空值替换(coalesce) |
coalesce函数可接受任意数量的参数,并返回第一个非空的参数。若所有参数均为空值,coalesce同样返回空值。 |
|
空值替换(ifnull) |
双参数版本的coalesce函数,返回第一个非空的参数。 |
|
判断为空(IS NULL) |
判断是否为空,返回布尔值。 |
列表相关
|
示例 |
帮助说明 |
|---|---|
|
长度(length) |
返回列表的成员数量,NULL成员也会被统计数量,用函数len和array_length效果一样 |
|
去重去空(list_distinct) |
去除列表中的所有重复值和NULL值,去重后无法保留原顺序。 |
|
去重去空计数(list_approx_count_distinct) |
列表成员去重、去NULL后,统计数量。函数list_unique也有同样效果,但其不适用于大数据场景,结果更精准但极大影响效率。 |
|
转文本(list_string_agg) |
将列表元素拼接为字符串,不去重,保留顺序。 |
|
成员排序(list_sort) |
对列表中的元素进行排序。list_sort最多可接受两个额外的可选参数:第二个参数指定排序顺序,可选ASC(升序)或DESC(降序);第三个参数指定空值位置,可选NULLS FIRST(空值在前)或NULLS LAST(空值在后)。 |
|
展平(flatten) |
展平一层,不会递归展平所有层级,也不会去重去NULL。 |
|
解包(unnest) |
将列表按一层层级展开为多行,这是一个会改变结果集行数的特殊函数。可通过max_depth参数限制递归展开的深度。解包空列表和NULL均会导致零行,如果您要解包的列可能为空列表或NULL,通常需要先进行处理,否则会导致返回的行数减少。 |
|
筛选(filter) |
从输入列表中筛选出使lambda函数返回true的元素构造为新列表。DuckDB必须能够将lambda函数的返回类型转换为BOOL类型。函数返回的类型与输入列表的类型相同。 |
|
区间(range) |
生成从start到stop范围内的值构成的列表。start参数包含在内,默认为0,stop参数不包含在内,允许指定增长的步长,默认为1。 |
其他
|
示例 |
帮助说明 |
|---|---|
|
类型转换(CAST) |
标准语法为:CAST(表达式 AS 类型名),还支持简写形式:表达式::类型名。 |
|
条件判断(CASE) |
CASE表达式会执行满足的条件后对应的表达式,当仅有一个条件时,也可使用IF(cond, a, b)来表示当满足cond则输出a否则输出b。 |
访问DuckDB官网以获得更多信息
根据版本信息,可访问DuckDB官网获得对应版本的语法帮助,以1.2版本为例,官网地址:https://duckdb.org/docs/1.2/sql/functions/overview
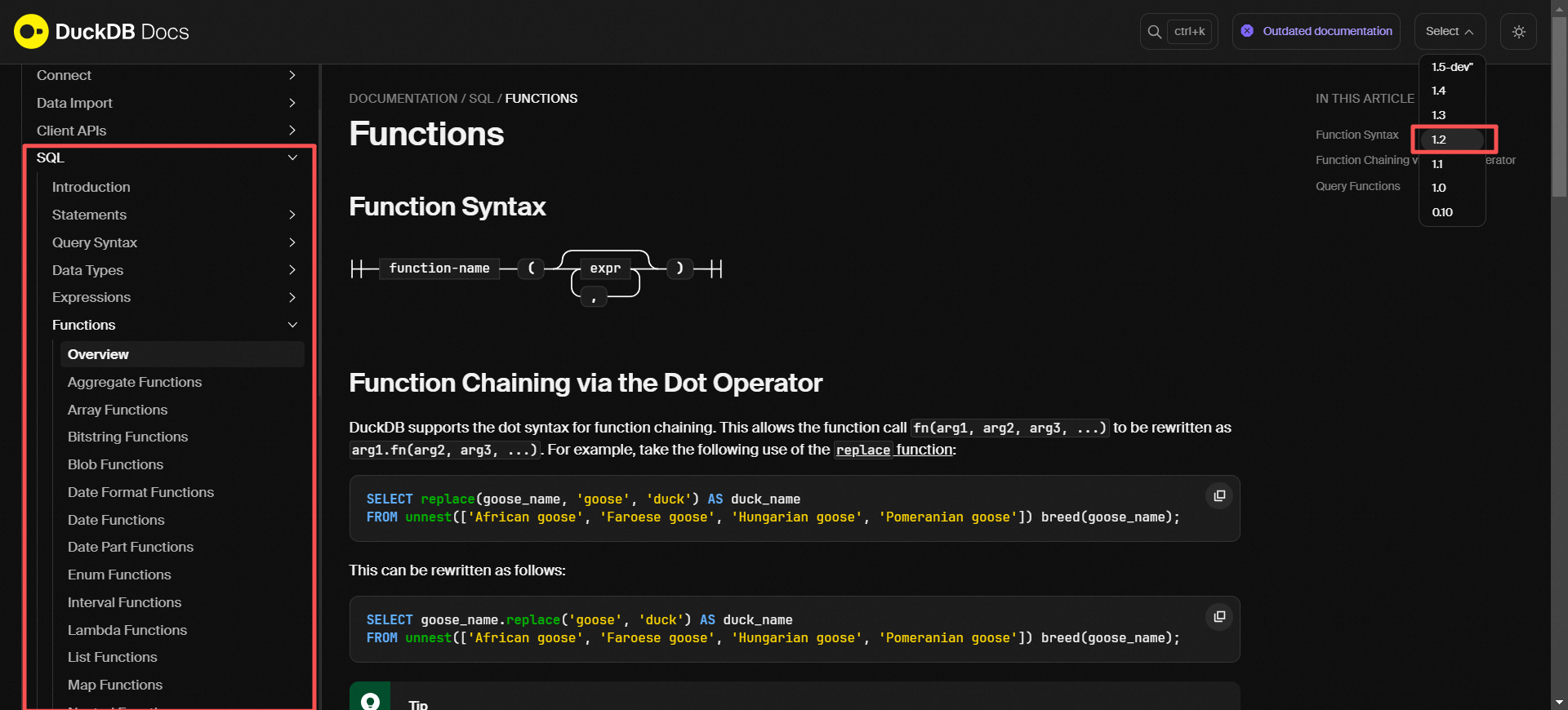
访问其中的具体章节,为您的具体问题提供更多建议。
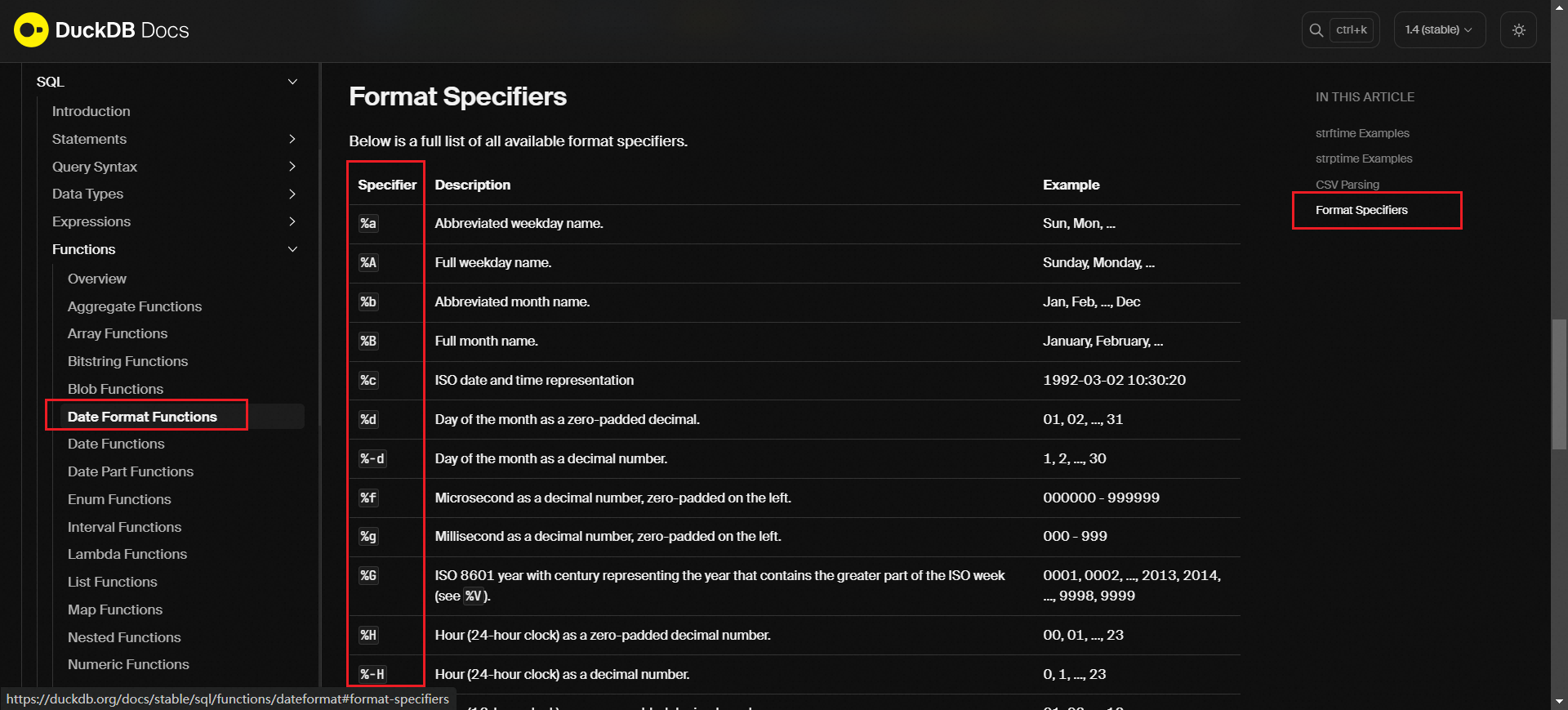
例如想查找更多的日期格式指定符号:
回到顶部
咨询热线
400-821-9199
