概述
版本记录
|
修订内容 |
版本号 |
发布日期 |
|---|---|---|
|
新建,包含开发的前五期内容 |
1.0 |
2025-01-01 |
|
补充 |
2.0 |
2025-04-01 |
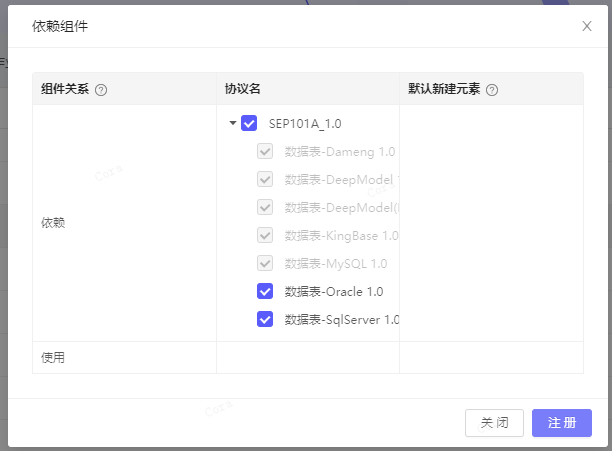
组件注册
组件部署后,空间管理员可注册【DeepPipeline】【3.0】版本:

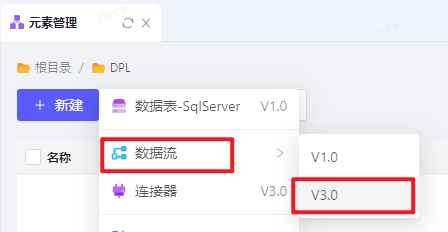
创建数据流
在元素管理或元素对象,都可创建数据流 3.0 元素。
进入画布后,初始画布会预置【开始】节点,不可删除不可复制,作为数据流执行的唯一起点。
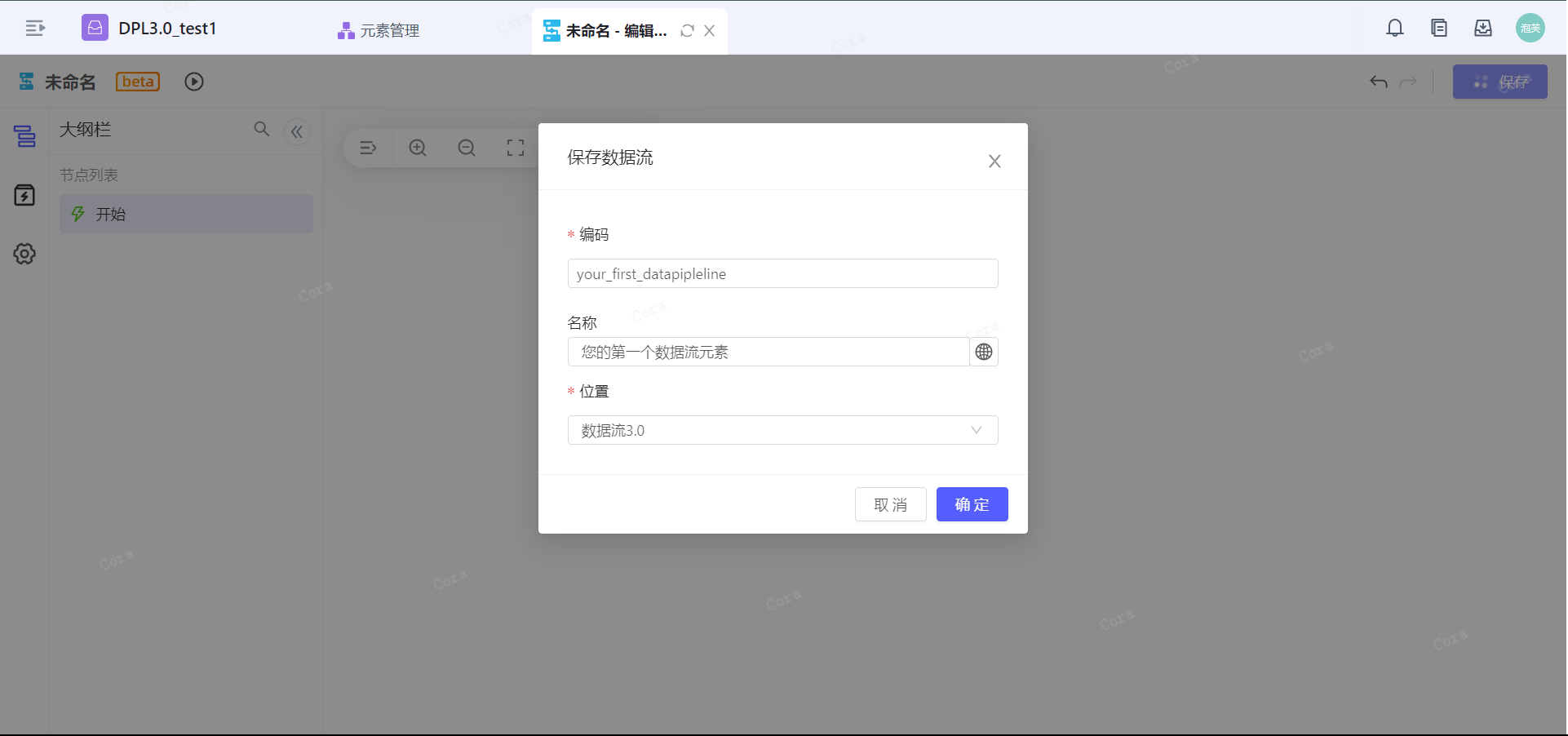
保存
用户可随时点击右上角保存按钮,输入元素编码和名称,以完成数据流的创建,生成对应的数据流元素。
保存前会进行校验,若校验出存在错误,则不允许保存,完整校验文档(仅供先胜内部成员查看):DPL_校验梳理。
校验不通过的内容会以表格样式展示在底部,点击每一行可以定位至具体配置处。
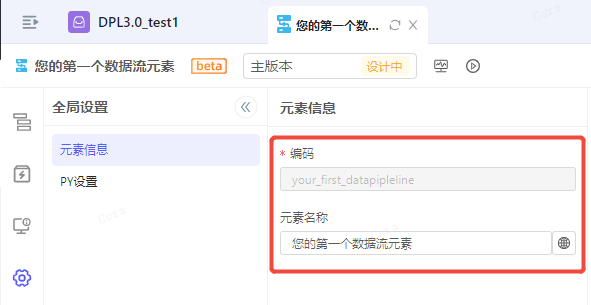
元素信息也可以在左侧菜单:设置->全局设置(元素信息)中进行编辑。
注意:元素保存后编码不可再更改,仅可通过元素管理中的元素重命名更改编码。
发布
数据流保存后,并未生效,仅作为设计版本,若需运行此数据流,则需要发布。
在主版本视图,可以点击右上角的发布按钮,将当前的已保存版本发布为正式版本,若有定时计划,则在发布成功后会开始定时运行。
发布需要进行相关校验,完整校验文档(仅供先胜内部成员查看):DPL_校验梳理,若校验不通过,会有对应错误提示。
启动触发
数据流的启动支持两种触发方式:
-
启动 api:通过调用 API 触发,此方式默认强制启用。在编辑态点击【手动执行】,或其他组件调用都为此种触发方式。
-
定时:通过 cron 表达式来定义定时计划,以固定时间间隔触发数据流,此方式为可选,启用之后需配置 cron 表达式。
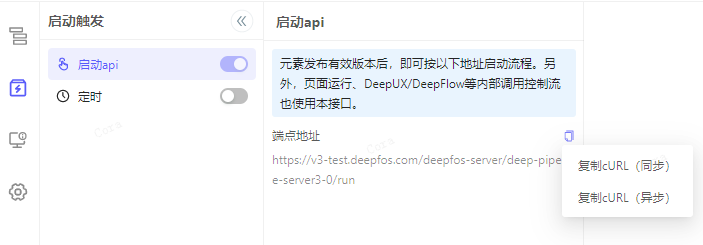
启动api
数据流元素保存之后,自动生成本数据流的端点地址,可快速复制同步或异步调用的 crul。
定时
可选配置,启用后必须配置 cron 表达式,cron 表达式支持 5 位,可以参考在线网站帮助生成:https://crontab.guru/。
数据流也提供了插入工具,以帮助您生成 cron 表达式:
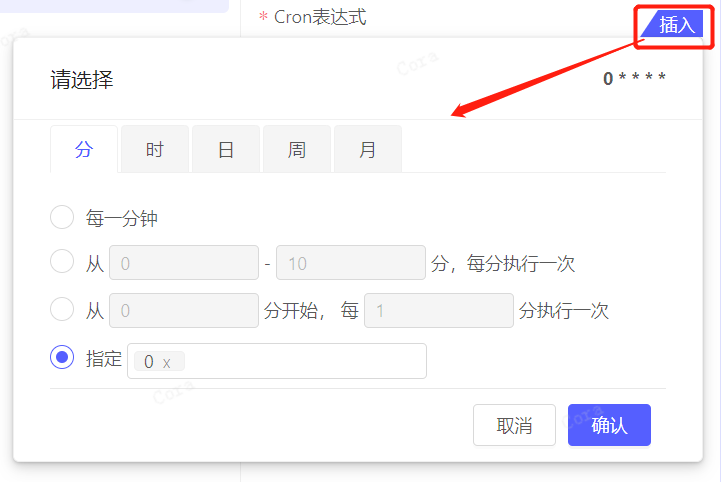
输入表达式后,会实时解析该规则的描述,展示在表达式下方,并且提供预览最近 10 次执行时间的功能,用以辅助您检查表达式是否正确。
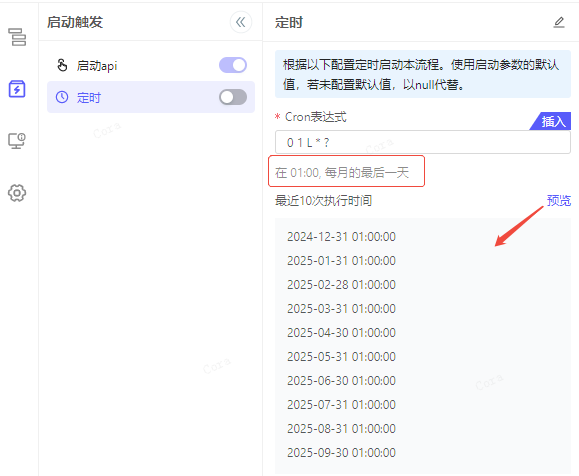
若数据流的已发布版本中,存在启用的定时计划,则会在到时后自动触发数据流,如需管理这些启用中的定时计划,可至数据流监控中进行统一管理。
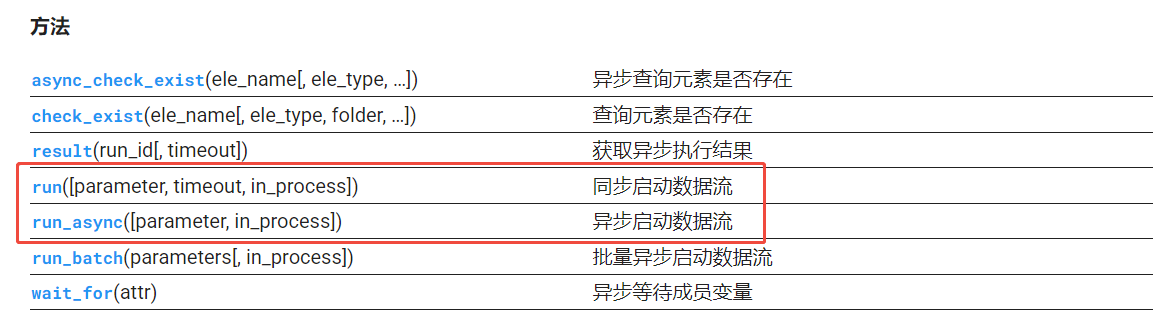
Python SDK
数据流提供了同步和异步启动的Python SDK,可查看对应文档:https://py.deepfos.com/deepfos/generated/deepfos.element.deep_pipeline.DeepPipeline.html#
数据流监控
数据流 3.0 组件注册后,在 app 中会预置deep_pipeline_monitoring元素,用以进行监控管理,可以将此元素添加至您的管理员菜单中。
在数据流元素的编辑页面,在顶部栏位置也提供了快速跳转监控元素的 icon,点击后可定位至该数据流元素的实例监控列表。

数据流监控分数据流实例和定时计划页签。
数据流实例
区分数据流元素,管理其所有的历史运行实例
-
左侧是数据流元素列表,可以进行查找、排序、设置显示元素编码或名称,可以快速跳转至元素编辑界面
-
右侧是该数据流元素的执行实例,可以对实例进行删除、终止、重新运行、查看日志等操作

定时计划
用于管理所有启用中的、设置了定时触发的数据流,可以对定时计划进行删除、终止、重新运行、查看日志等操作。

节点
概述
数据流节点目前归类如下:
|
分类 |
分类描述 |
节点编码(默认) |
节点名称 |
节点描述 |
语雀文档 |
|---|---|---|---|---|---|
|
开始 |
数据流执行的唯一起点 |
start |
开始 |
数据流执行入口 | |
|
标准 |
自动化任务节点,输出结果为非数据集 |
pycode${N} |
PY代码 |
用于执行输入的 PY 代码,输出结果为非数据集 | |
|
py_script${N} |
PY脚本 |
调用python2.0元素 | |||
|
conn_operate${N} |
连接器操作 |
选择目标连接器元素,提交【增删改】操作 | |||
|
datatable_operate${N} |
数据表操作 |
选择目标数据表元素,提交【增删改】操作 | |||
|
http_api${N} |
HTTP API |
标准化的 API 接口集成,通过界面配置快速完成API请求的编排与响应处理 | |||
|
pipeline${N} |
数据流 |
调用数据流3.0元素 | |||
|
数据集-查询 |
数据管道类节点,仅查询,输出结果为数据集 |
ds_conn_query${N} |
连接器查询 |
选择目标连接器元素,通过 UI配置或 SQL 语句,查询输出数据集结构的数据 | |
|
ds_datatable_query${N} |
数据表查询 |
选择内置业务数据源,通过 UI配置或 SQL 语句,查询输出数据集结构的数据 | |||
| ds_export${N} | 导出 | 导出数据集,可在调试结果或数据流监控中下载文件 | 20250331迭代待开发 | ||
|
数据集-转换 |
数据管道类节点,对数据集进行转换处理,输出结果为数据集 |
ds_ui_transform${N} |
UI 转换 |
选择前序需要处理的数据集节点,通过 UI配置按步骤处理行列,输出结果为数据集 | |
|
ds_pivot${N} |
透视 |
选择前序需要透视的数据集节点,支持透视和逆透视,输出结果为数据集 | |||
|
ds_sql_transform${N} |
SQL 转换 |
用于执行输入的 SQL 语句,输出结果为数据集 | |||
|
ds_py_transform${N} |
PY 转换 |
用于执行输入的 PY 代码,输出结果为数据集 | |||
|
逻辑 |
特殊的逻辑节点,分支、响应、缓存等 |
branch${N} |
条件分支 |
用于条件编排,各条件内容输入 PY 代码,符合条件则进入对应的后续分支 | |
|
response${N} |
响应 |
数据流运行的返回结果,输入 PY 代码,会将其序列化为JSON后返回 |
各节点的详细配置和使用案例请进入对应章节查看。
公共配置
即使是不同节点,大多数都有以下公共配置,在此处一并说明,在各具体节点不再赘述。
节点列表
大纲栏中展示节点列表,可以对具体节点进行:编辑、删除、复制。
高级
-
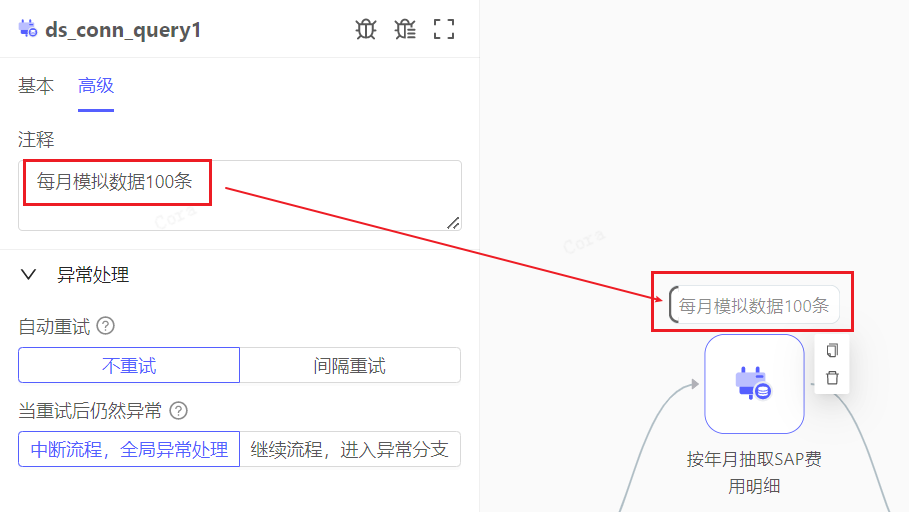
注释:用于节点的进一步描述,会展示在画布中的节点上方
-
异常处理:当该节点在执行中出现异常时,进行的后续处理
-
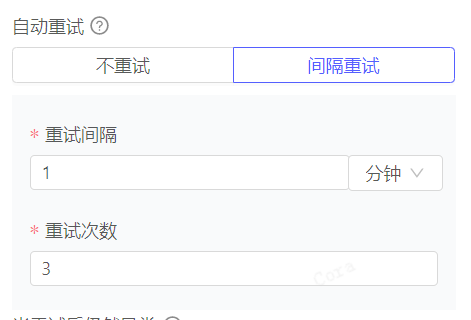
自动重试:支持按固定间隔重试多次
-
当重试后仍然异常:选择是否中断流程,或是进入异常分支

-
调试
每个节点的右上方都有两个调试按钮:调试本节点、带前序节点一同调试。
某些支持在节点内细分步骤的节点,例如UI转换,则调试本节点表示
带前序节点一同调试表以下图为例,说明这三种调试会执行的节点范围:

|
当前节点 |
当前选中步骤 |
调试本节点 |
带前序节点一同调试 |
|---|---|---|---|
|
节点 2 |
- |
节点 2 |
开始 -> 节点 1 -> 节点 2 |
|
节点 3 |
- |
节点 3 |
开始 -> 节点 3 |
|
节点 4 |
步骤 2 |
节点 4 的步骤 1 -> 步骤 2 |
开始 -> 节点 1 -> 节点 2 |
调试相关结果会展示在调试栏,调试栏包含的内容如下。
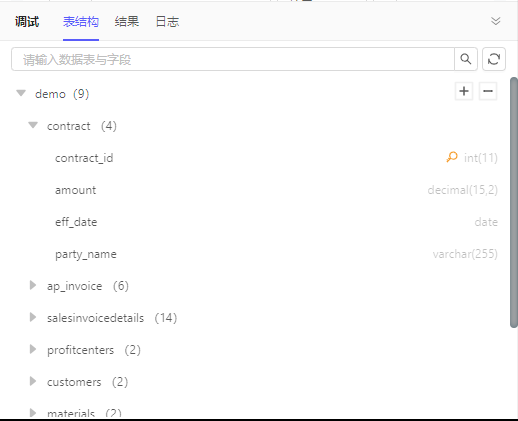
表结构
某些节点会获取数据源的 schema 信息,例如连接器查询、数据表查询等节点,会在选择数据源后,展示该数据源的 schema,例如:
结果-数据
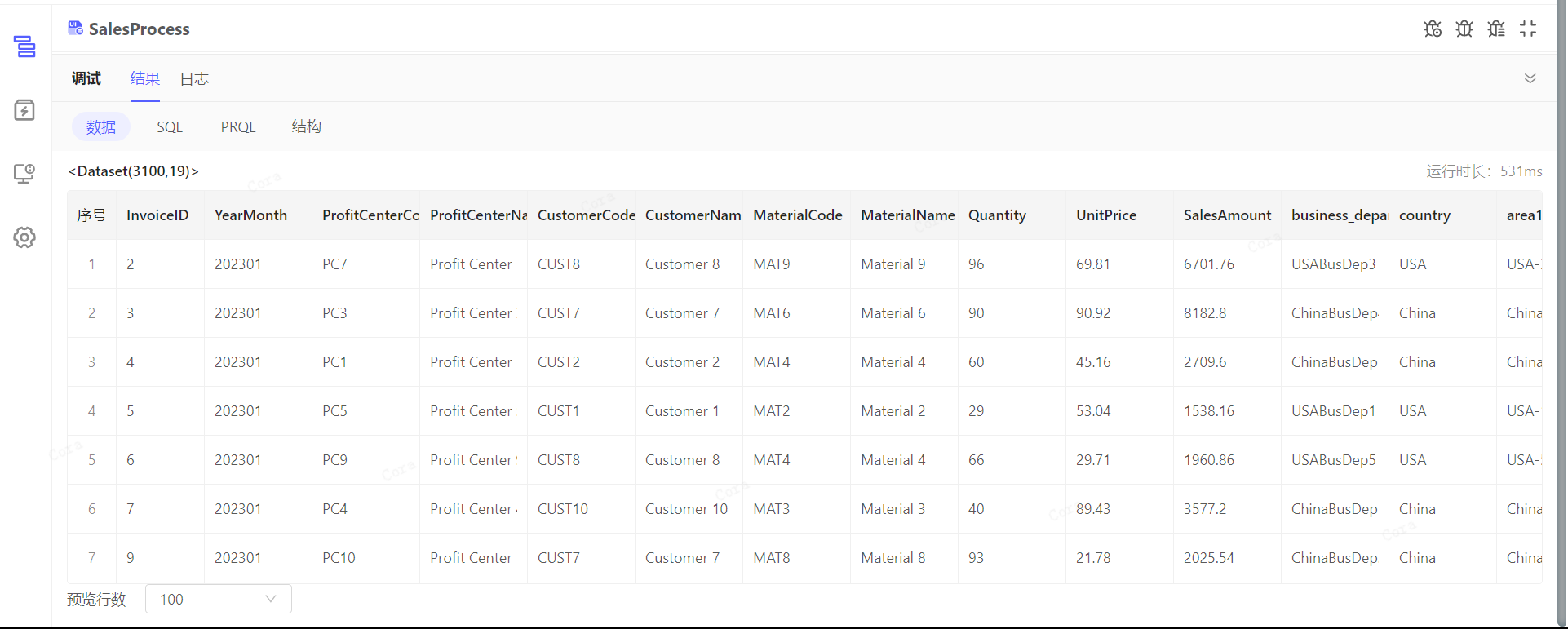
调试后的数据结果,非数据集结果的样式与数据类型有关:
数据集结果为表格样式:
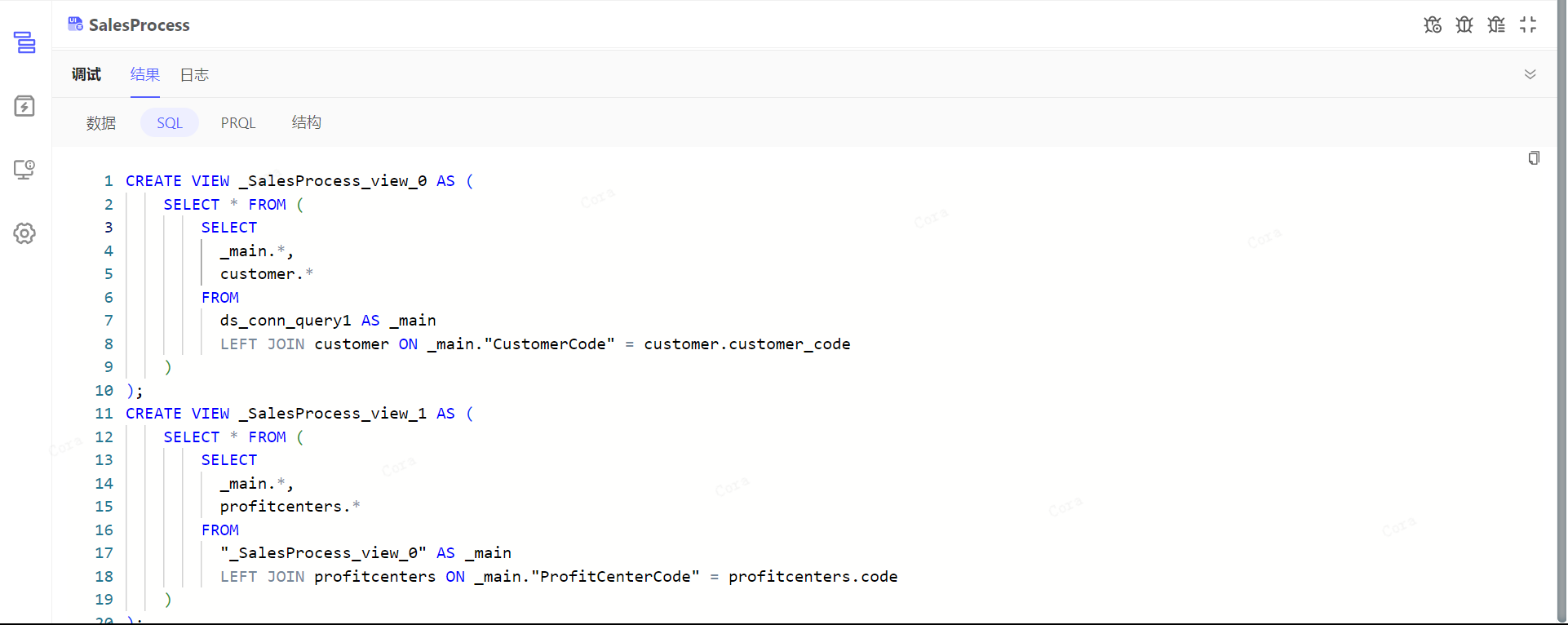
结果-SQL
某些节点利用 DuckDB 实现,会提供配置项转换后实际执行的 SQL 语句,以便排查问题。
结果-PRQL
某些节点利用 PRQL 实现步骤转换 SQL,会提供配置项转换后的 PRQL 语句,以便排查问题。
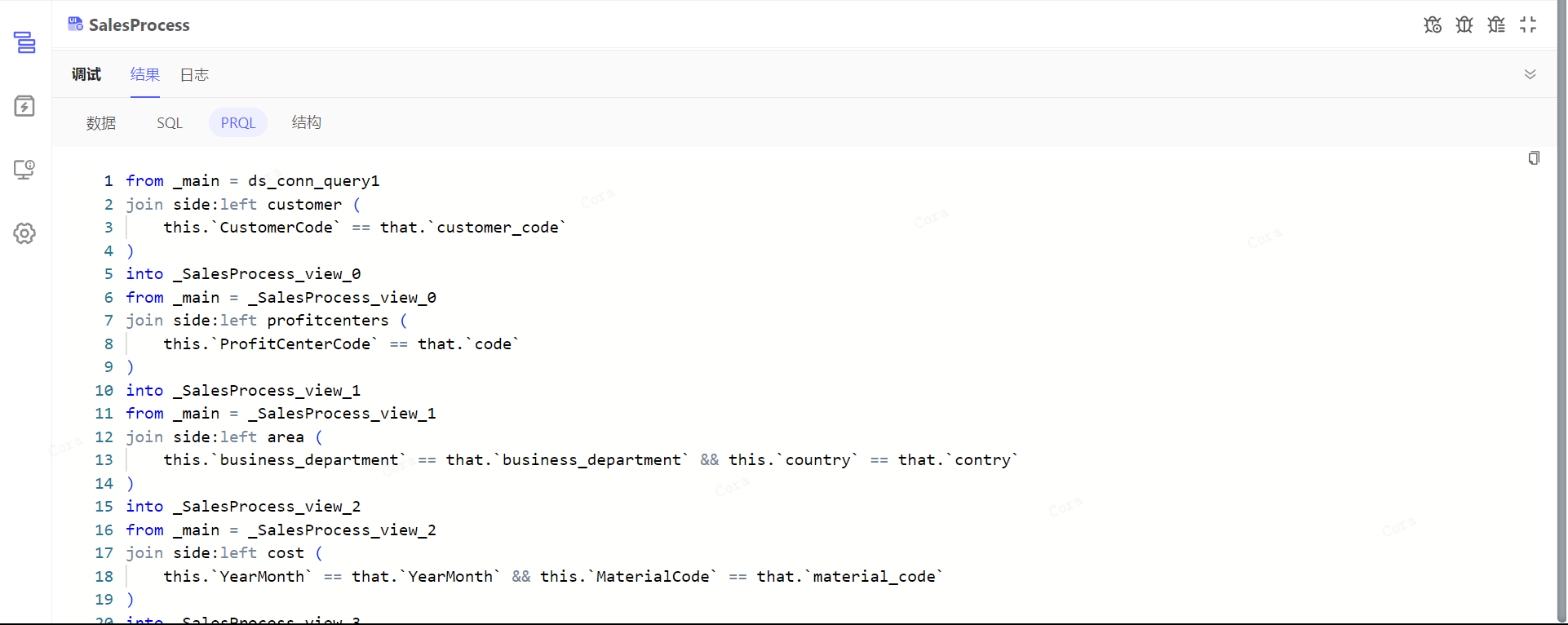
结果-统计
输出结果为数据集的节点,可对调试结果进行统计分析。
统计范围为调试得到的完整结果,包括因预览数量限制而未展示的数据。
关于占比数量的特殊说明:
-
大于 99% 且小于 100% 的数值,会显示
> 99% -
小于 1%且大于 0%的数值,会显示
< 1%
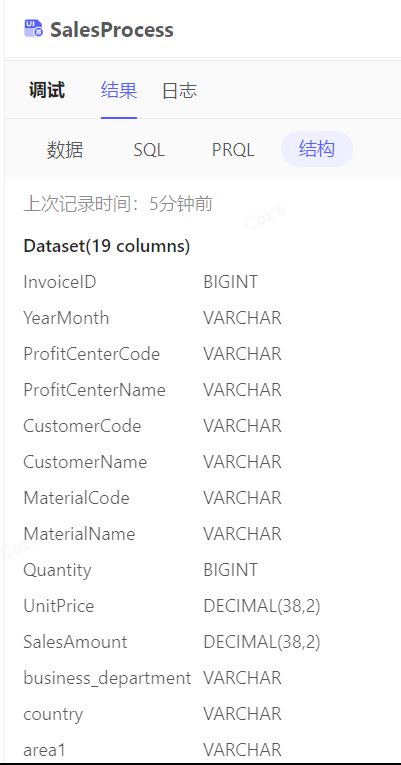
结果-结构
此节点调试后的数据结构:
日志(暂无)
记录该节点的调试日志:
变量
在各节点的配置中,经常会引用到前序节点的信息或全局配置的某些属性,我们提供了系统预置变量,以供在各节点配置时使用。
完整的变量体系见下表,引用方法参考示例列的表达式列,例如想要引用节点 node1 的运行结果,则输入 Operator.node1.data 即可。
异常处理
当数据流执行出现异常,支持的后续处理,例如通知、数据修复等等。
邮件通知
支持向指定邮箱发送相关异常信息。
开启后允许输入邮箱地址,多个地址需要用半角逗号,隔开。
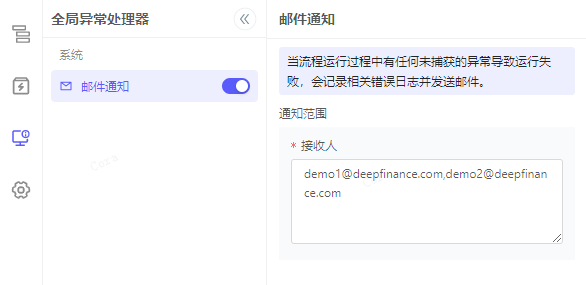
邮件内容示例:
机器人通知
支持添加多个渠道的机器人,添加机器人需要为其命名,并输入Webhook地址,通过Webhook调用机器人。
目前支持的渠道包括:钉钉、飞书、企业微信。
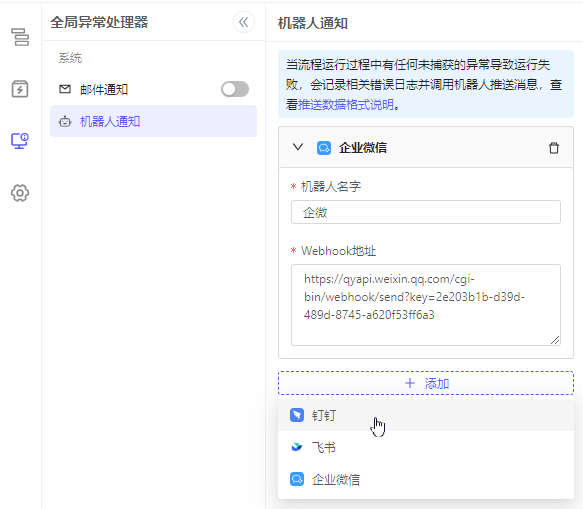
各渠道的推送数据不相同:
-
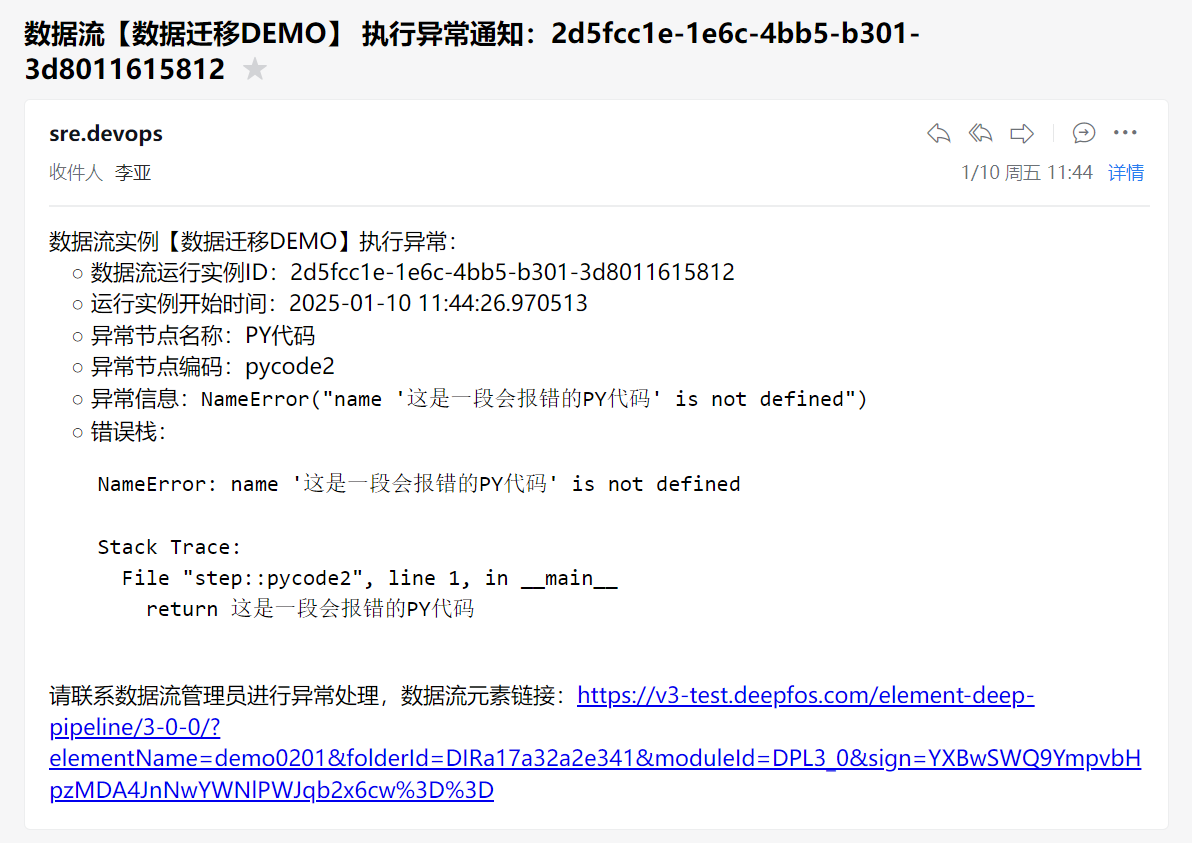
钉钉和企业微信终端无需额外配置,直接展示推送的内容,内容格式固定,涵盖数据流的以下信息:-
元素名称
-
元素链接
-
实例 ID
-
实例名称
-
实例开始时间
-
异常节点名称
-
异常信息
-
-
飞书还需要自行配置机器人才能实现发送通知的功能,因此我们为飞书渠道提供了更丰富的数据,页面上可以预览数据格式以便您配置机器人
以下是我们对各个渠道推送的数据格式说明,及其各渠道相关的Webhook文档,供开发人员参考:
-
企业微信(markdown类型的消息):https://developer.work.weixin.qq.com/document/path/91770#%E6%96%87%E6%9C%AC%E9%80%9A%E7%9F%A5%E6%A8%A1%E7%89%88%E5%8D%A1%E7%89%87
{
"msgtype": "markdown", //消息类型:markdown
"markdown": {
"content":""//符合markdown语法的消息内容
}
}
-
钉钉(markdown类型的消息):https://open.dingtalk.com/document/orgapp/custom-bot-send-message-type?spm=ding_open_doc.document.0.0.69cf227d0KuBEo
{
"msgtype": "markdown", //消息类型:markdown
"markdown": {
"title": "数据流执行异常通知", //首屏会话透出的展示内容
"text": "" //符合markdown语法的消息内容
}
}
{
"data": {
"subject": "数据流【XX】 执行异常通知:XX数据流实例ID", //消息标题
"content": "请联系数据流管理员进行异常处理\n实例名称: XX数据流实例\n开始时间: 1900-01-01 00:00:00}\n异常节点: 节点1,节点2\n异常信息: 异常1,异常2\n数据流元素: [点击跳转](当前数据流元素URL})", //消息内容
"element_name": " XX数据流实例", //异常数据流元素名称
"element_url": "当前数据流元素URL", //异常数据流元素链接
"run_id": "XX数据流实例ID", //异常的数据流运行实例ID
"run_name": "XX数据流实例", //实例名称
"start_time": "1900-01-01 00:00:00", //异常实例的运行开始时间
"node_name": [
"节点1",
"节点2"
], //导致异常的节点名称
"node_code": [
"code1",
"code2"
], //导致异常的节点编码
"error_msg": [
"异常1",
"异常2"
] //异常信息
}
}
全局设置
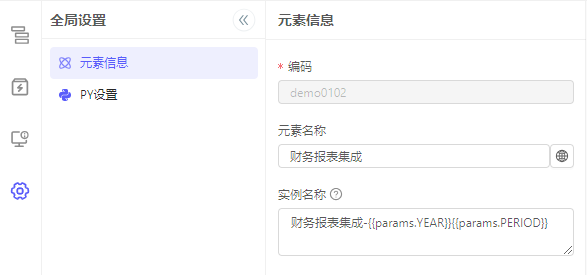
元素信息
用于配置元素相关信息。
-
编码:元素保存后,编码不可修改,元素管理员可进入元素管理管理界面使用
重命名功能修改编码。 -
实例名称:是发起的每一条实例的名称,同一个数据流元素发起的多个实例,可以拥有不同的实例名称,以区别不同实例,未配置实例名称时,则用元素名称默认。
-
配置实例名称时可用双花括号{{}}占位,在括号内可引用原始启动参数params,并用
.或者[]访问成员值 -
例如,原始启动参数是:
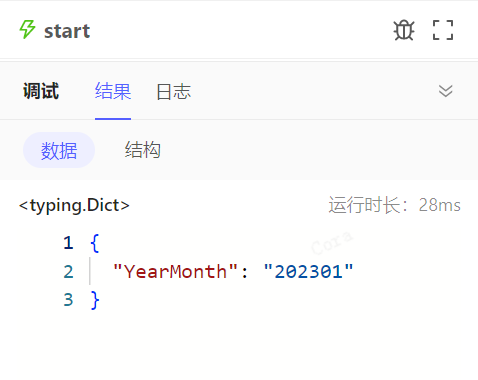
{"YEAR":"2023", "PERIOD":"01"},实例名称配置为财务报表集成-{{params.YEAR}}{{params.PERIOD}},则可以得到财务报表集成-202301 -
流程监控中会展示流程实例的实例名称,用户通常以此来直观区分不同实例
-
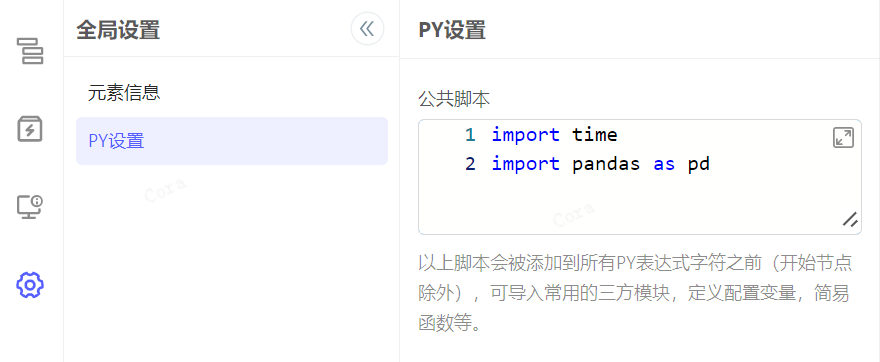
PY 设置
用于配置 PY 节点的公共代码。
案例
自查手册
回到顶部
咨询热线
400-821-9199
