选择前序需要处理的数据集节点,通过 UI配置按步骤处理行列,输出结果为数据集。
节点配置
-
节点内按步骤配置,执行时会按顺序依次执行
-
步骤 0 为数据源,必须配置,后续步骤自行添加
-
步骤支持命名、删除、排序
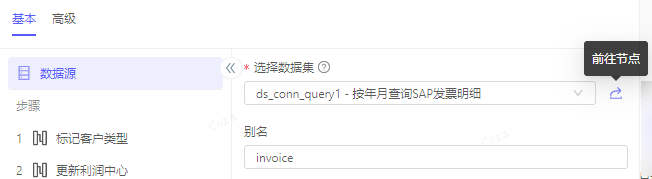
数据源
-
选择数据集:
-
选择需要操作的前序数据集节点
-
提供快速跳转按钮,可以定位至该数据集节点的配置界面
-
-
别名:非必填,可为该节点定义别名,后续引用时可以使用别名
步骤分类
目前支持的步骤包括:
|
分类 |
分类描述 |
步骤 |
用途 |
|---|---|---|---|
|
行操作 |
仅改变原数据集的行数,不影响列数 |
行过滤 |
按条件筛选数据 |
|
行去重 |
全部列或指定列的数据重复时,删除重复行 | ||
|
行排序 |
按指定列升序或降序排列数据 | ||
|
行选择 |
按目前排序,仅挑选第几行到第几行的数据 | ||
|
列操作 |
增减原数据集的列,不改变行数 |
列选择 |
仅保留需要的字段,或排除不需要的字段并保留剩余字段 |
|
列类型转换 |
+ 增加新列,如果定义的新列字段名与原有列重名,则覆盖原有列 | ||
|
列计算 |
+ 增加新列,如果定义的新列字段名与原有列重名,则覆盖原有列 | ||
|
列计算-窗口 |
+ 增加新列,如果定义的新列字段名与原有列重名,则覆盖原有列 rank函数,以得到【名次】 | ||
|
列计算-窗口聚合 |
+ 增加新列,如果定义的新列字段名与原有列重名,则覆盖原有列 | ||
|
集合 |
原数据集的行列可能都被影响 |
聚合 |
+ 增加新列,如果定义的新列字段名与原有列重名,则覆盖原有列 类型按价格倒序排的前5条数据的平均值 |
|
连接(join) |
再选择一个前序数据集节点作为 | ||
|
集合(union) |
再选择一个前序数据集节点,将其与数据源计算 |
行过滤
使用条件编排器进行过滤条件编排(详见DPL_专用编辑器)
行去重
-
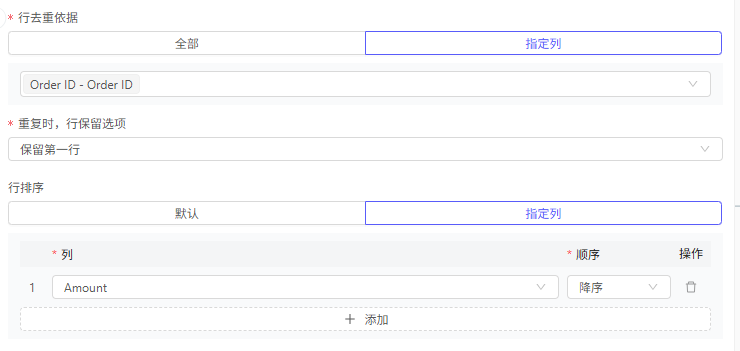
行去重依据
-
全部:仅当全部列的值完全相同时,视为重复数据
-
指定列:选择某几列,当这几列的值完全相同时,视为重复数据
-
-
重复时,行保留选项:
-
保留第一项:只保留第一项,其余的行删除
-
-
行排序:
-
针对于【保留第一项】,可以对【第一】进行排序,例如按金额倒序排序,则金额最大的则成为第一,实现保留金额最大的选项
-
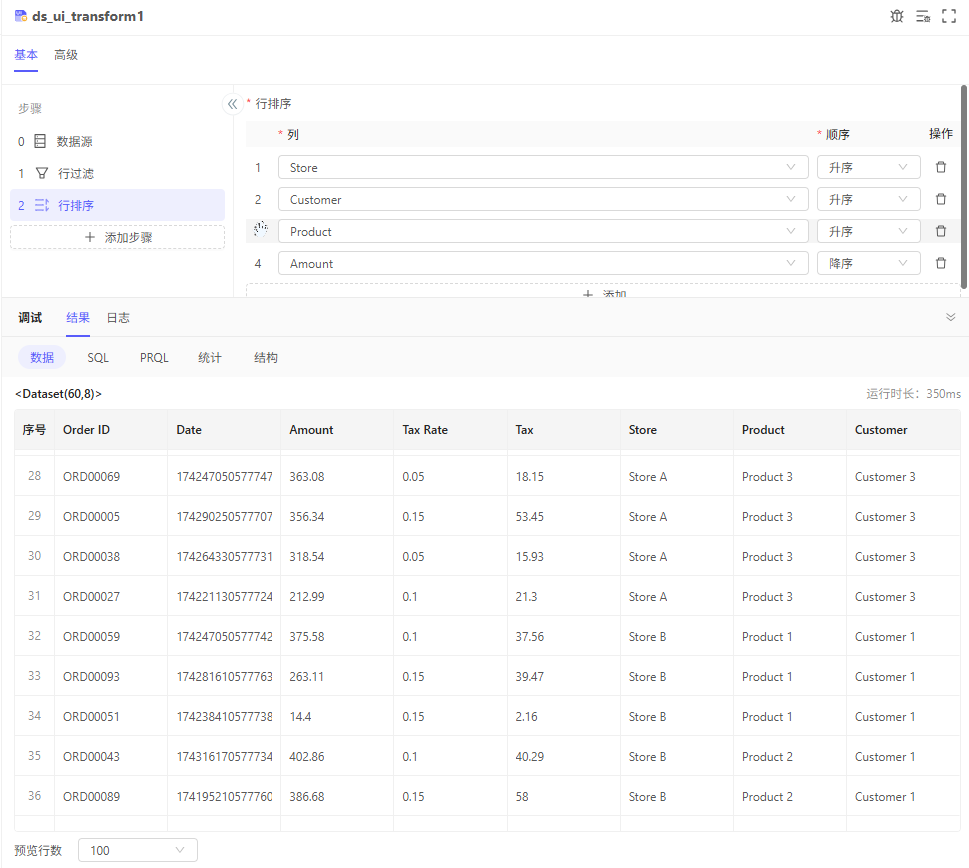
行排序
按指定列升序或降序排列,多个字段间排序的优先级顺序可拖拽调整
行选择
选择从第几行到第几行,常用排序后保留前几条数据的场景。
-
从:可选
首行或输入第几行 -
至:可选
末行或输入第几行
列选择
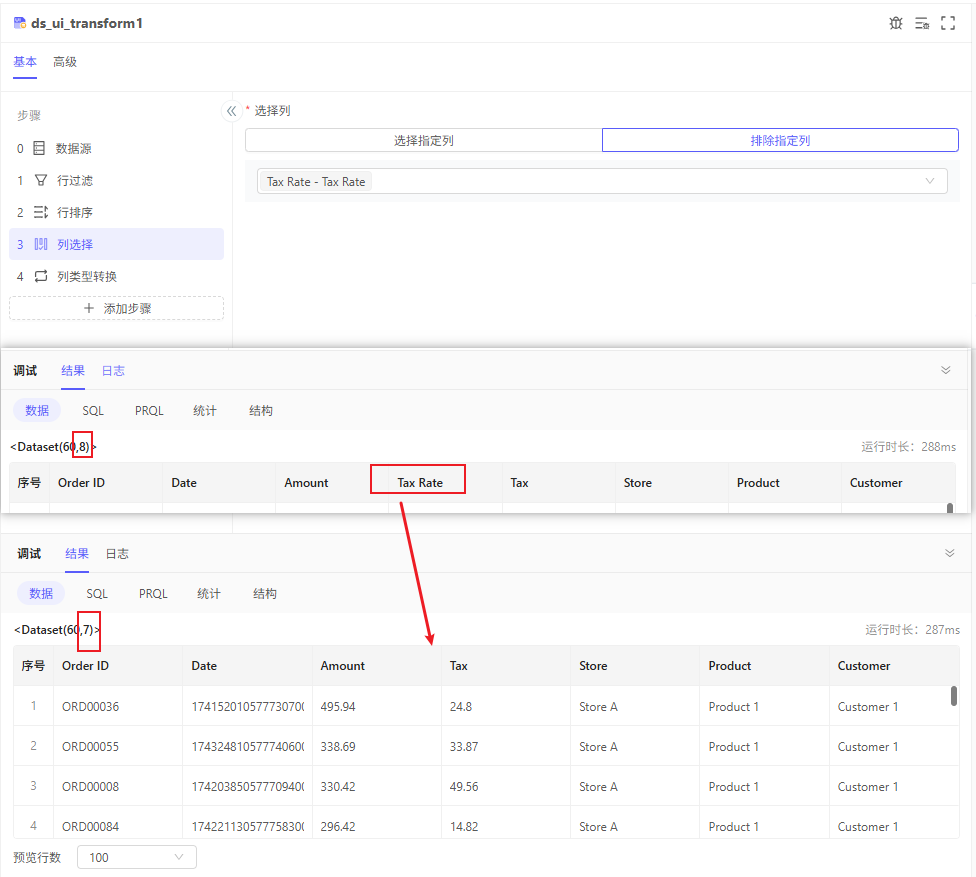
当数据的无用列较多时,可以正向选择要保留哪些列,或者排除哪些不需要的列只保留剩下的列。
PS:排除指定列对于存在列拓展的情况更为友好。例如:原始列A、B、C,排除列C,则本步骤后,只保留列A、B,若后续列扩展为A、B、C、D,无需修改配置,会自动添加列D,得到列A、B、D。

列类型转换
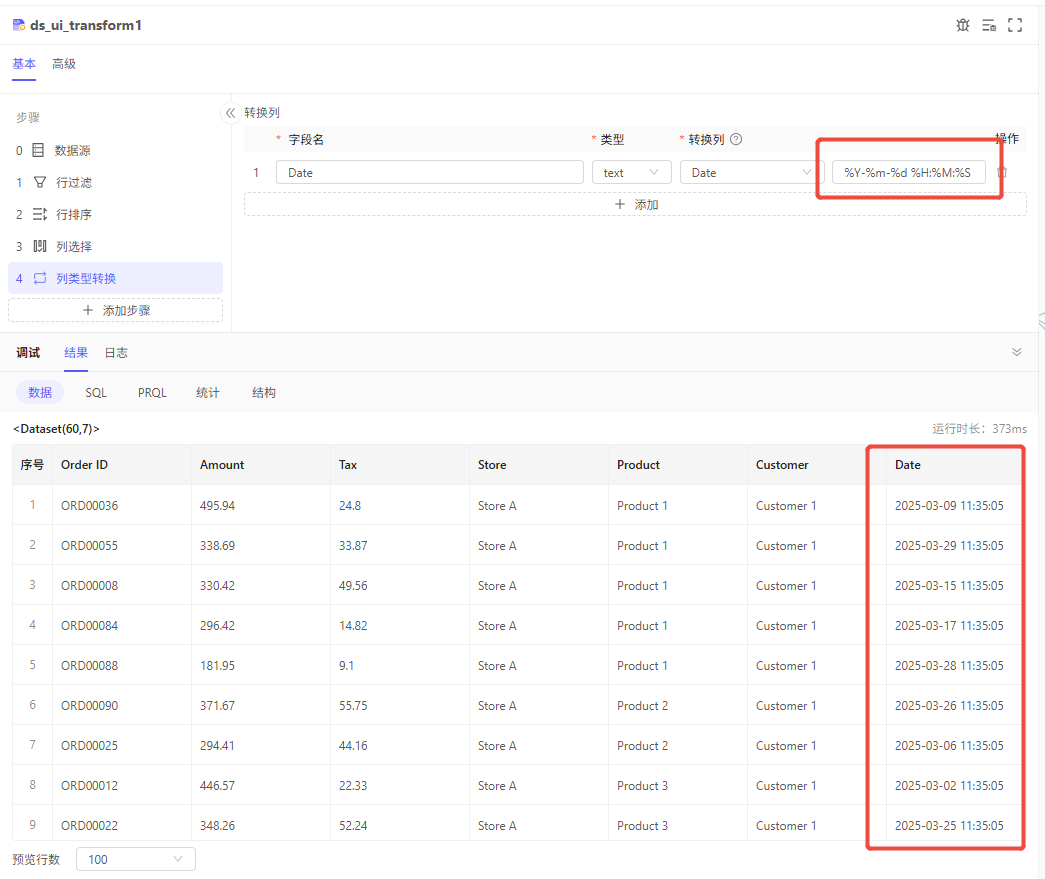
用于将原字段的类型转为指定类型,需要为转换后的字段命名,若与已有字段重名,会覆盖原字段。
date、datetime类型的字段转为text类型字段时,需指定转换后的日期时间格式。其中,%Y表示年,%m表示月,%d表示日等。

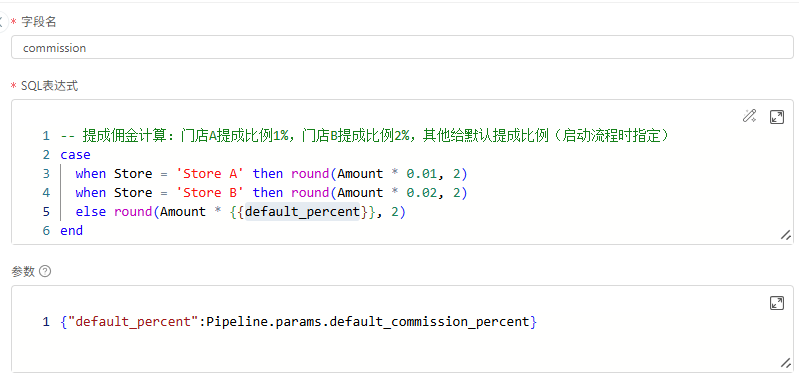
列计算
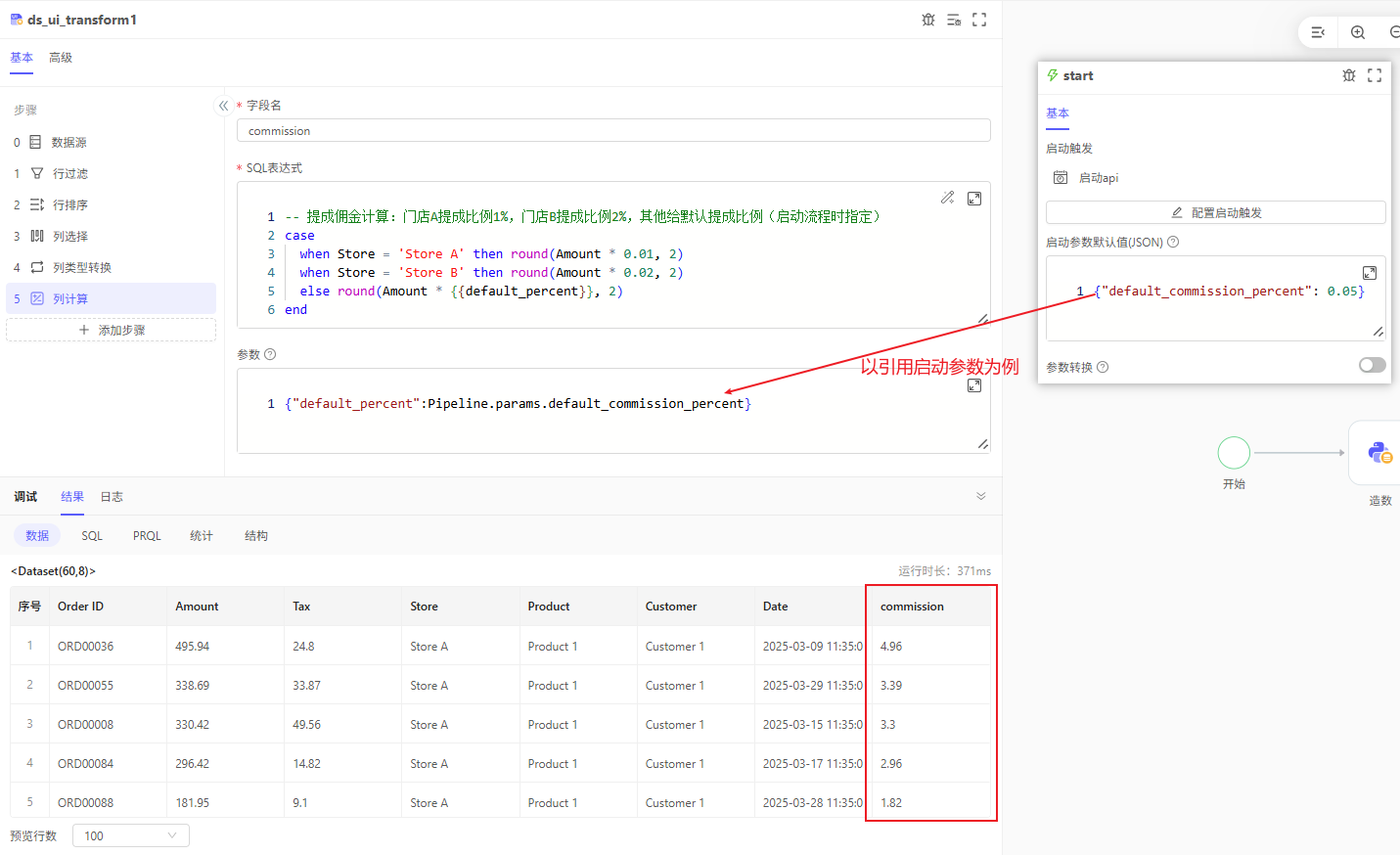
利用SQL计算得到新字段,需要为新字段命名,若与已有字段重名,会覆盖原字段。
SQL语法需要符合 DuckDB 要求,请参考其官方文档:SQL Introduction。
-
SQL中可以使用参数,参数需要用双花括号{{}}占位,并在括号中定义参数名。
-
在参数赋值框中,输入PY表达式,为定义的参数赋值,PY表达式中可以使用数据流的预置变量,例如启动参数或前序节点的输出结果等。
列计算-窗口
窗口函数就像是给数据开了一个”观察窗口”,让你能够在不改变原始数据行数的情况下,对数据进行分组计算和分析。
想象你在教室里看成绩单:
-
普通聚合函数(如SUM、AVG)就像老师宣布全班平均分
-
窗口函数则像是给每个学生发一张小纸条,上面写着:”你的语文分数是X1,全班平均分是Y1,你在全班排名第Z1;你的数学分数是X2,全班平均分是Y2,你在全班排名第Z2”
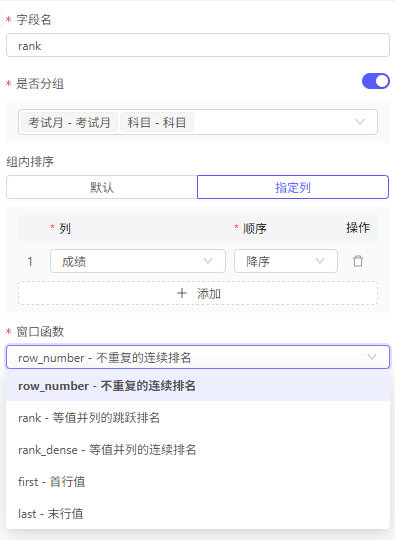
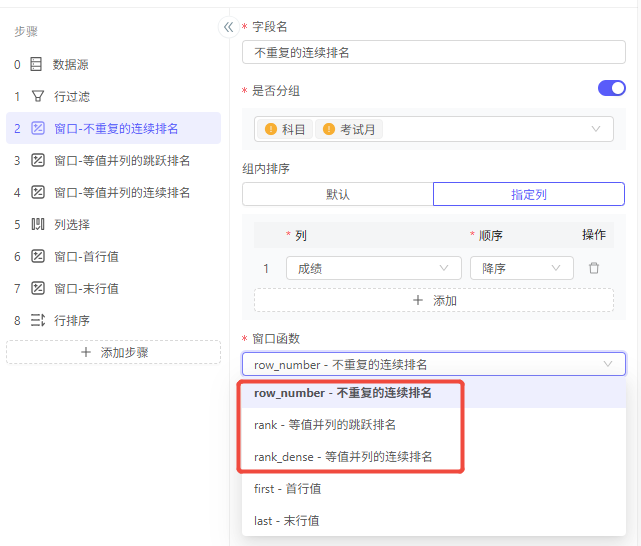
排名函数包括:
-
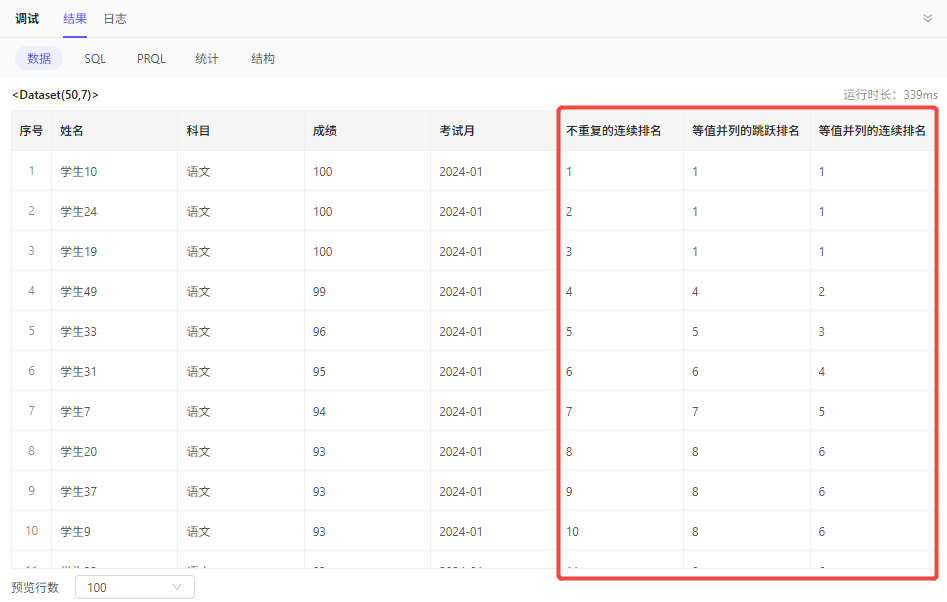
row_number - 不重复的连续排名:即使值相同,也会拥有不同排名
-
rank - 等值并列的跳跃排名:值相同的排名一定相同,当出现多个排名相同的,例如有N个相同,下一个排名会出现跳跃,在当前排名上会+N
-
rank_dense - 等值并列的连续排名:值相同的排名一定相同,当出现多个排名相同的,下一个排名在当前排名上仅+1
这三种排名的区别,举例说明:
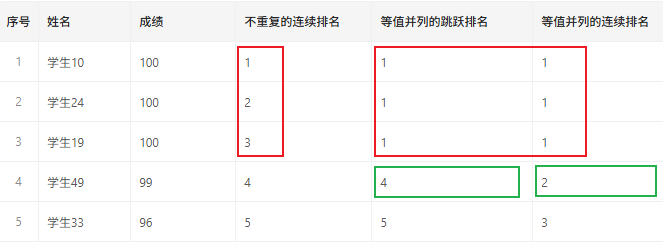
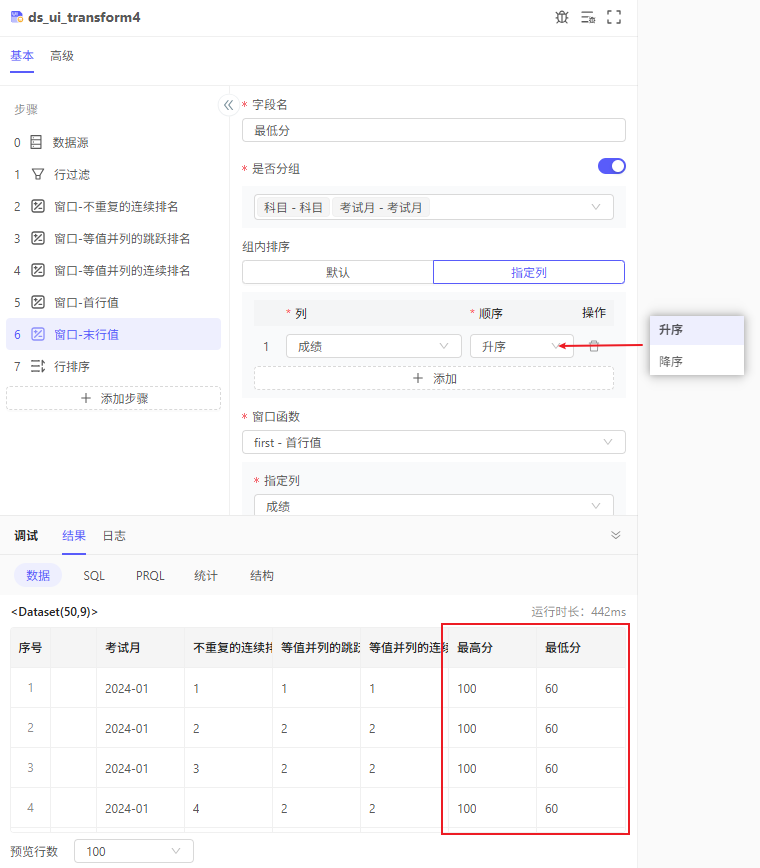
first - 首行值用于取窗口中的第一行中,指定列的值。例如取成绩单上的最高分、最低分等。
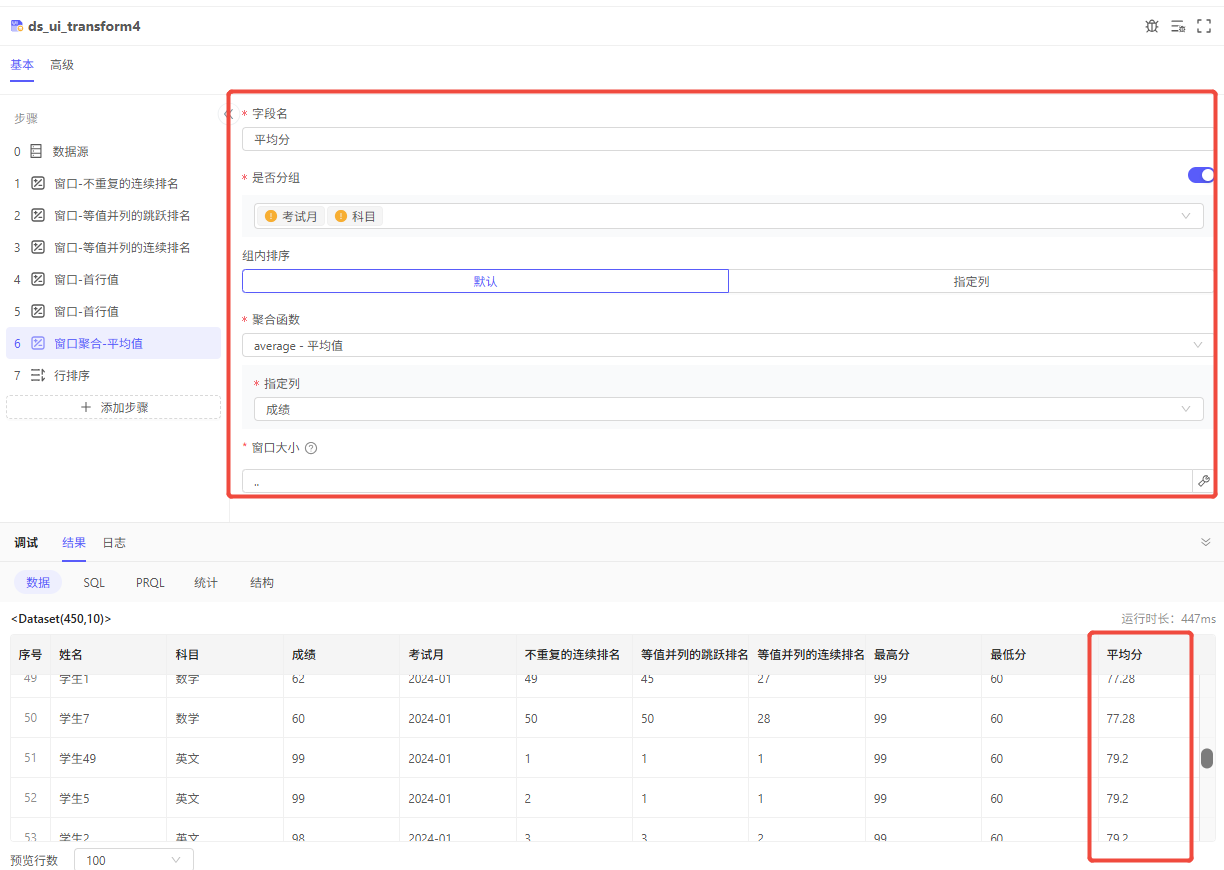
列计算-窗口聚合
与列计算-窗口的思路相同,只是在列计算-窗口的基础上:
-
提供了更多与聚合相关的函数。例如:sum - 求和、count - 计数、count_distinct - 去重计数、min - 最小值、max - 最大值、average - 平均值、stddev - 标准差、all - 与、any - 或
-
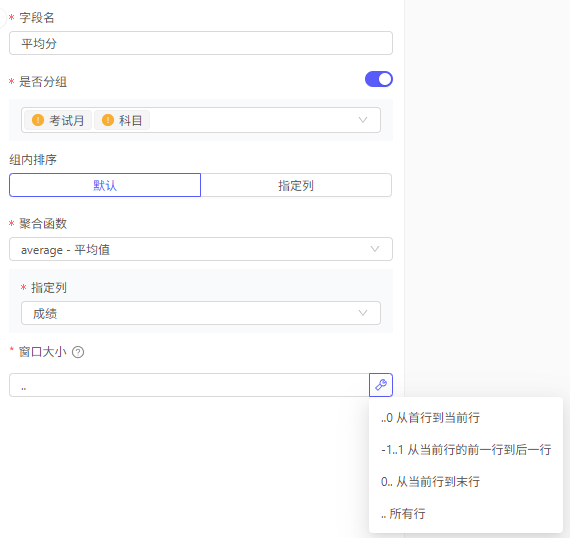
可以指定分组后的窗口大小。例如,选择
从首行到当前行作为窗口大小,来实现至今累计
PS:指定窗口大小时,0表示当前行,-N表示往前第N行,N表示往后第N行,..前的数字省略表示从首行,..后的数字省略表示至末行
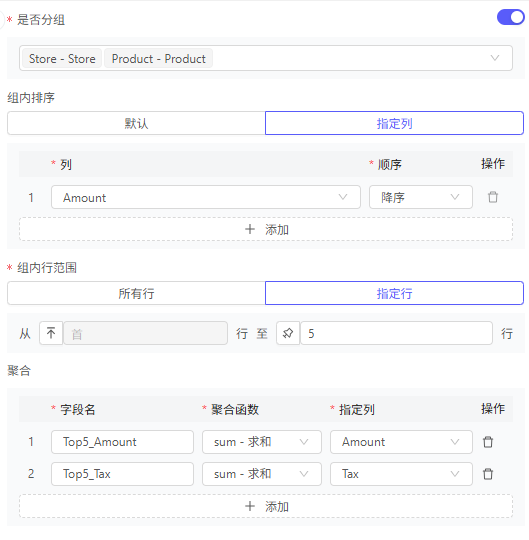
聚合
支持对原数据集:
-
按指定规则分组
-
分组后,进行排序
-
各组内,挑选排序后的数据,例如仅保留前5行
-
各组内,对保留的数据应用聚合函数,例如求和、计数、平均值···
与窗口函数不同,聚合后,会改变原数据集的行列,只保留分组条件和聚合字段。
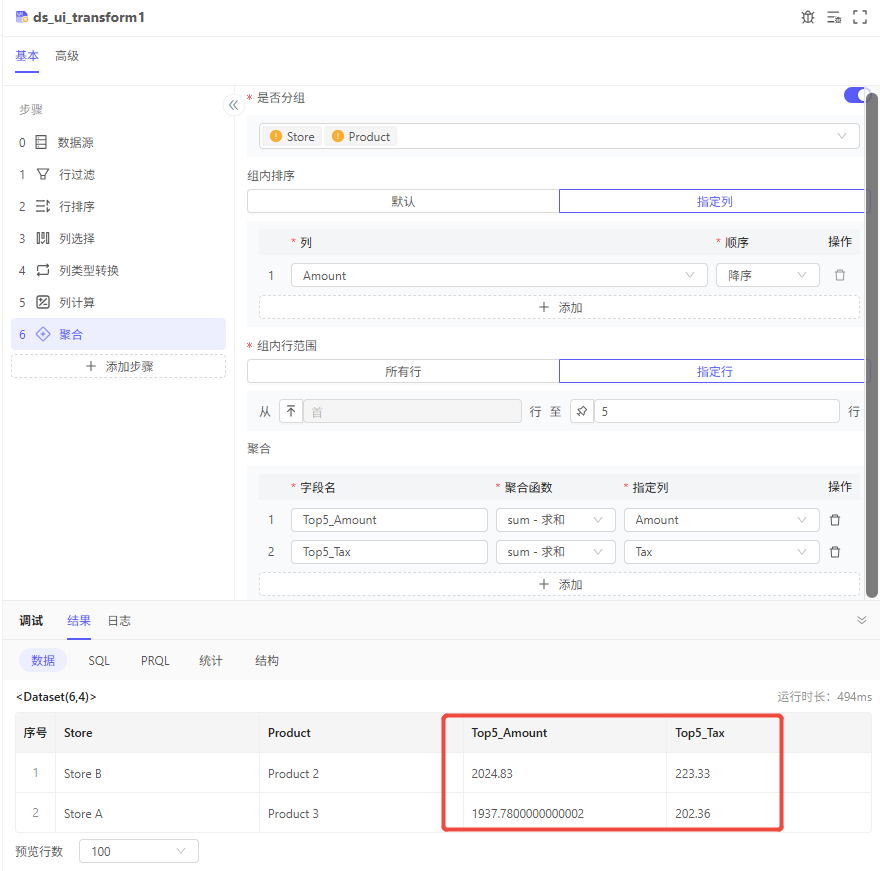
例如,针对于全年销售数据,要统计各门店&产品下,销售量前5的订单,销售金额一共是多少、一共交了多少税费:
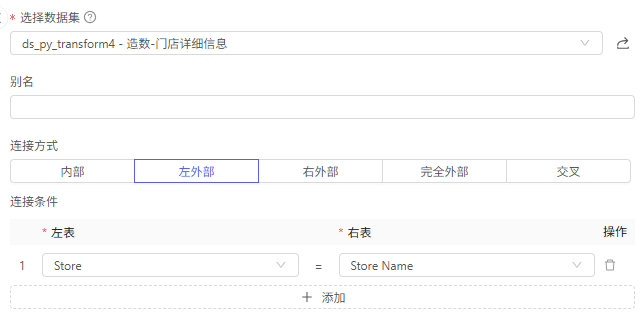
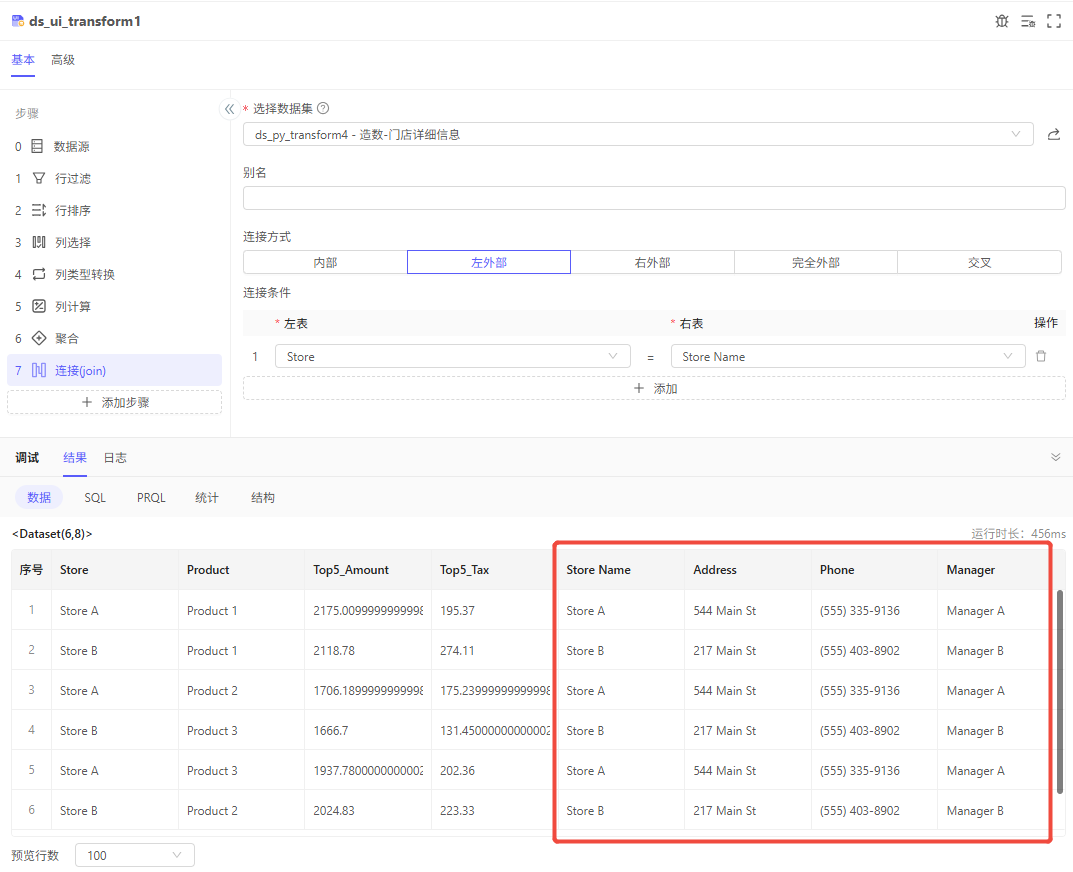
连接
选择一个前序数据集节点作为右表,将其与本节点的数据源(左表)进行连接,需要选择连接方式和匹配字段。
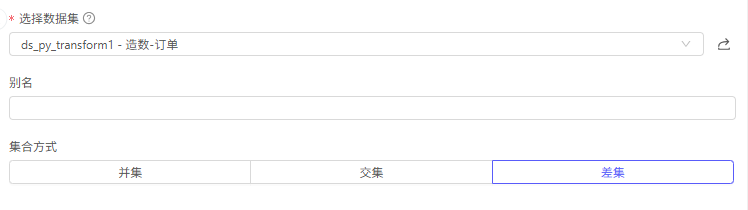
集合
再选择一个前序数据集节点,将其与数据源计算并集/交集/差集
使用案例
元素导入包:ds_ui_transform.zip
样例数据
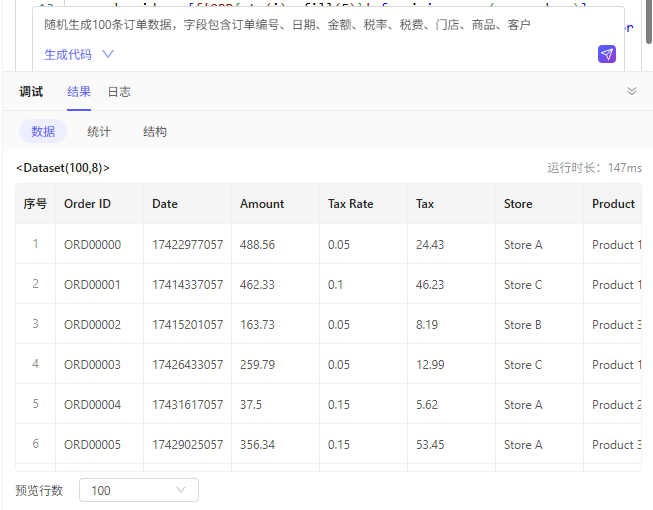
使用UI转换节点,借助智能AI助手,生成100条样例数据。
提示语参考:随机生成100条订单数据,字段包含订单编号、日期、金额、税率、税费、门店、商品、客户
行过滤
需求:筛选出【门店A和门店B】中,订单金额>100或者税率≥10%的订单数据。
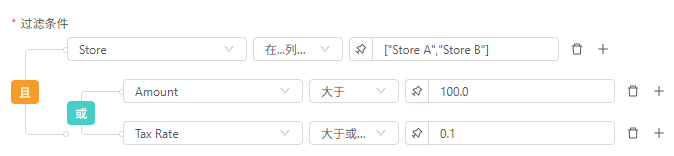
筛选后:
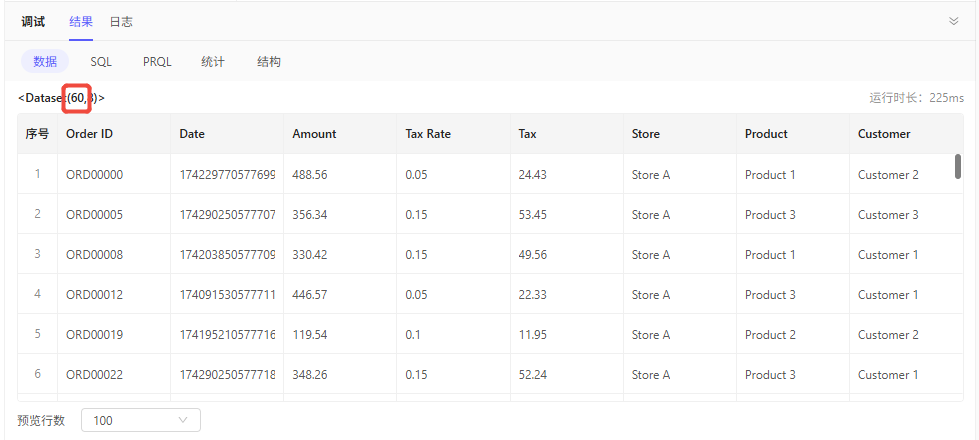
行去重
造数:使用UI转换节点,借助智能AI助手,在【造数】结果的基础上,复制其中前十条数据,复制出的新数据的Amount在原Amount基础上加100,再拼接回原【造数】数据中,按订单编号升序、Amount降序排序,所以前10条数据的订单编号是重复的,但是金额不一样:
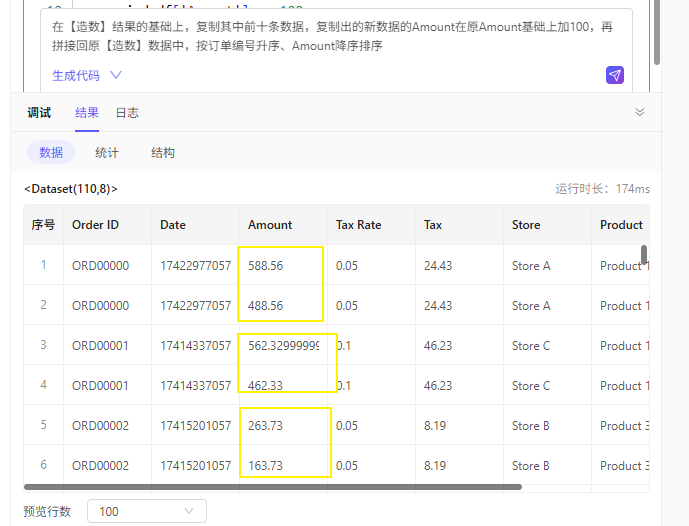
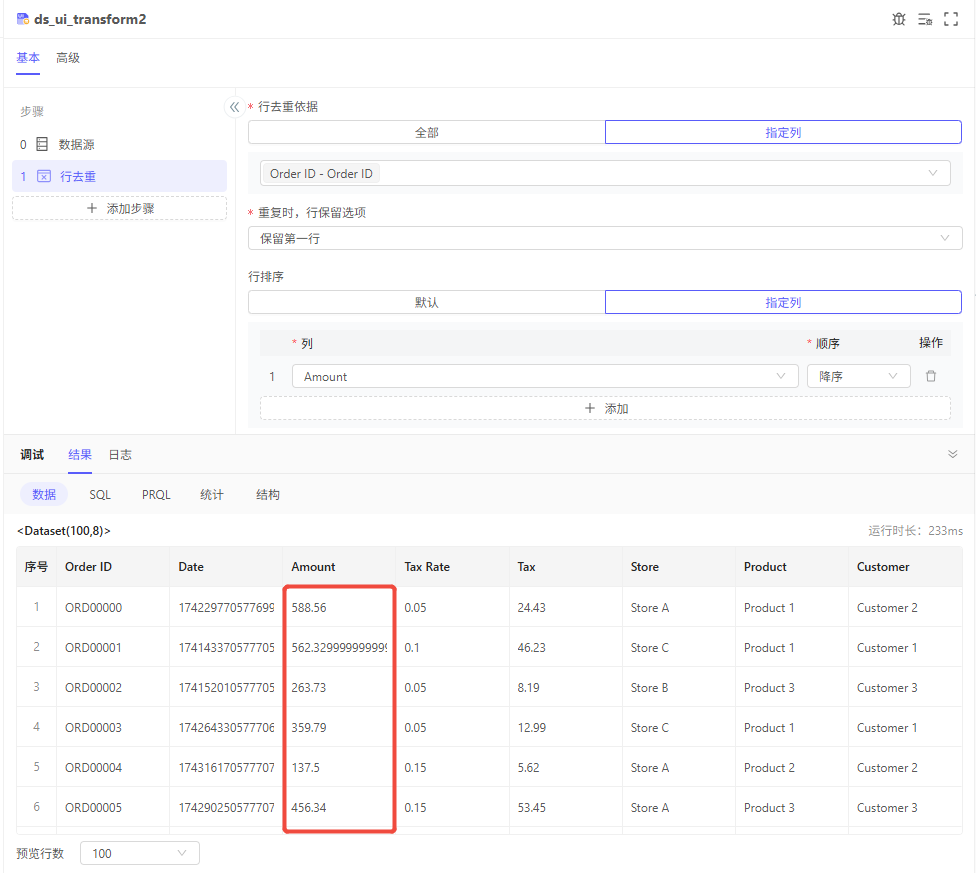
需求:按Order ID去重,Order ID一样的,保留金额大的那条
行排序
需求:按门店、客户、商品升序排序后,再按金额降序排序。
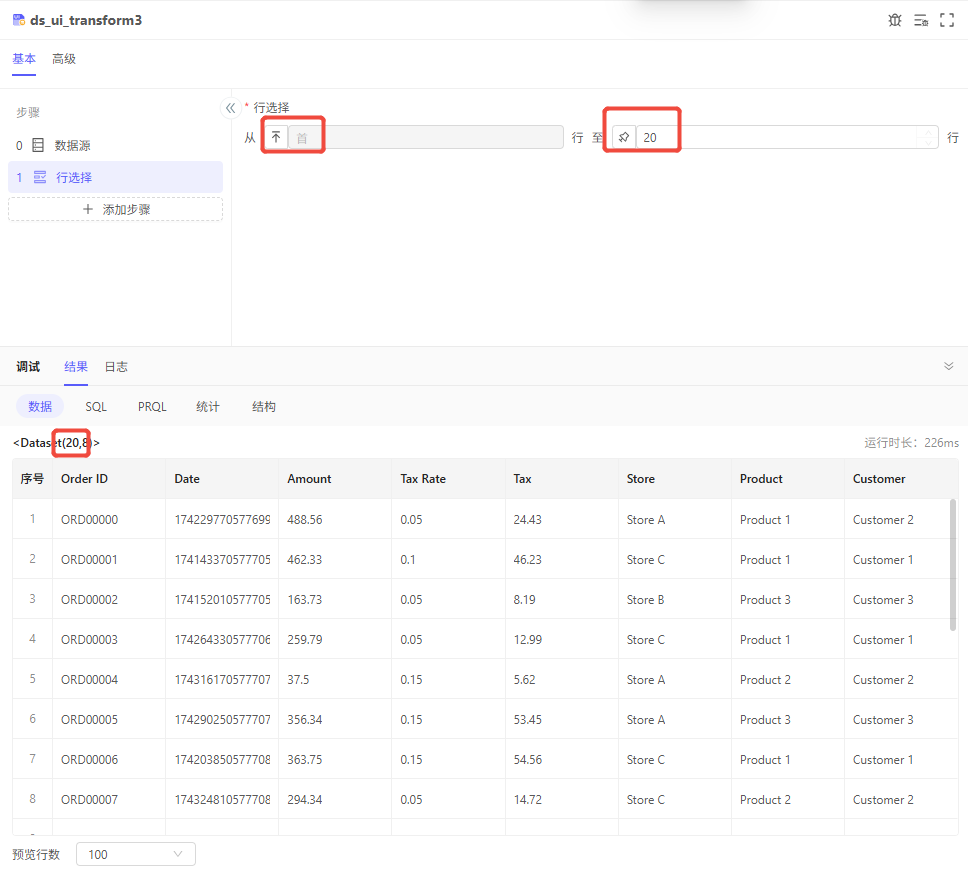
行选择
需求:仅选择前20行
列选择
需求:排除无用列Tax Rate
列类型转换
需求:日期时间转换为指定格式的文本
列计算
需求:按门店计算提成佣金。
列计算-窗口
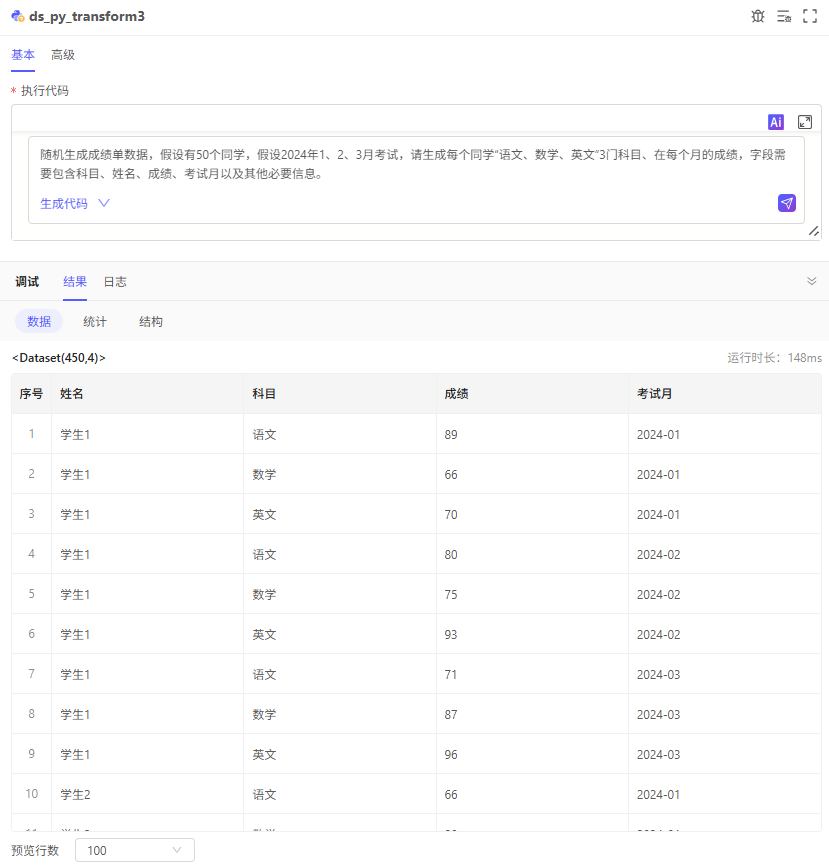
需求:有一份包含每月的各科考试成绩的成绩单,需要直观看出每次考试中,每位同学在各科目的排名情况,以及本次考试中,本科目的最高分和最低分。
成绩单用AI智能助手生成一份模拟数据:
三种排名方式:
效果:
取最高分和最低分:
列计算-窗口聚合
需求:接窗口的案例,还需要计算每次考试中,各科目的平均分
聚合
需求:针对于全年销售数据,要统计各门店&产品下,销售量前5的订单,销售金额一共是多少、一共交了多少税费。
连接
需求:订单表上只有门店编号,需要拿到门店的更多信息。
集合
需求:现在有一份掺杂了重复旧数据和有新数据的新数据集:
-
通过
差集,新数据集 - 旧数据集,可以取出本次新增数据 -
通过
并集,本次新增数据 u 旧数据集,可以取出不重复的有效数据 -
通过
交集,新数据集 n 有效数据,检查出有重复的数据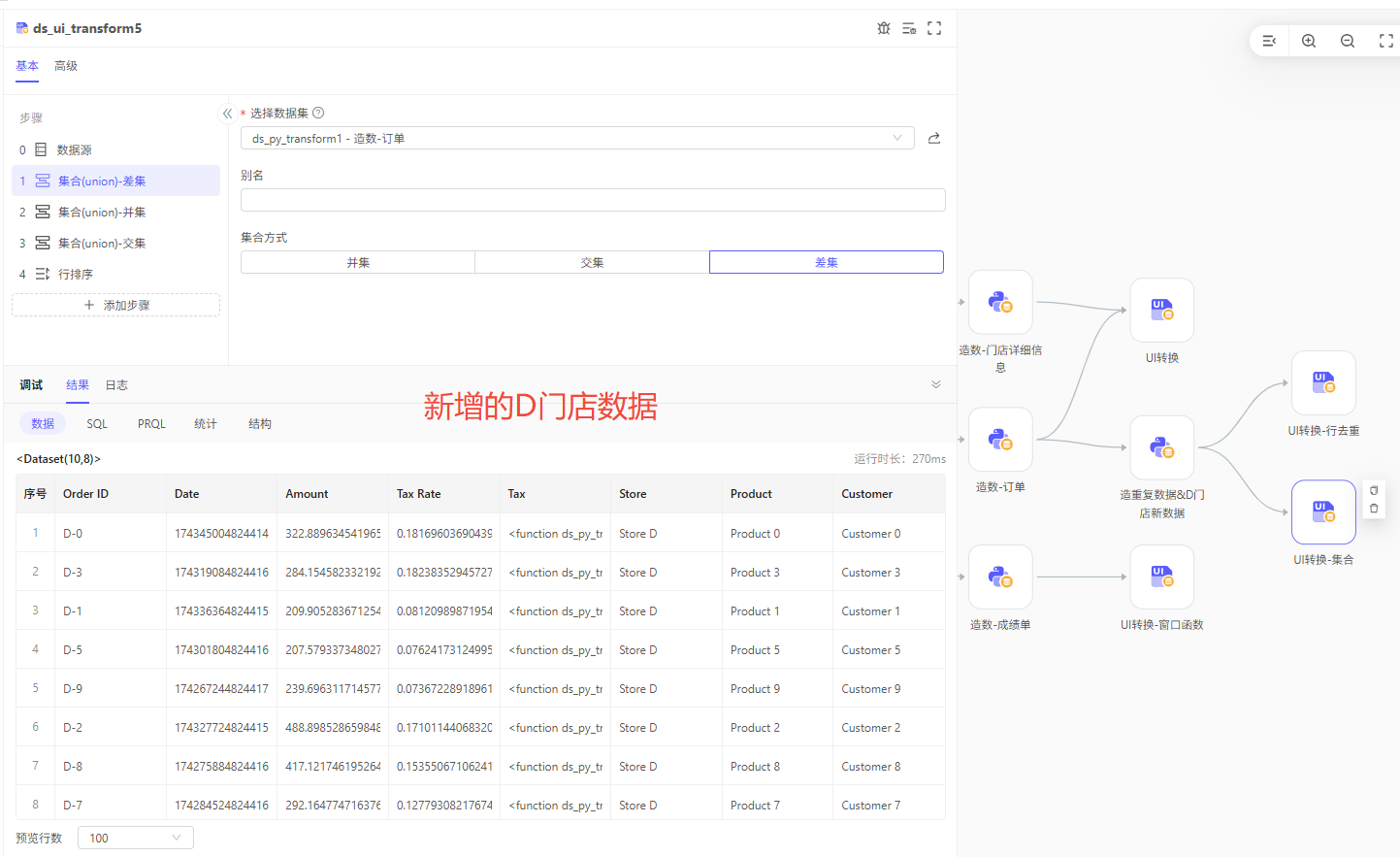
回到顶部
咨询热线
400-821-9199
