关键概念
1. 核心逻辑
数据流工作的本质就是将一堆数据从一个地方搬运到另一个地方。
我们可以用物流来做非常形象的类比,数据流的工作和物流工作其实并没有什么很大的区别。
物流公司从一个客户(一个数据源)那边取得需要运输的货物(数据),然后打包装箱搬上车(将数据加载至流管道中),运输到**另一个客户(另一个数据源)**手中。
实际的业务可能比图中的要复杂得多,往往我们需要从多个数据源中取数,然后经过一系列的数据处理和清洗,再将最后的数据结果传入指定的另外一个或多个数据源。
也像物流一样,有时候是把货从一个人手里送到另一个人手里,有时候是从一个仓库送到另一个仓库,有时候是商家的仓库发给购买的人等等。
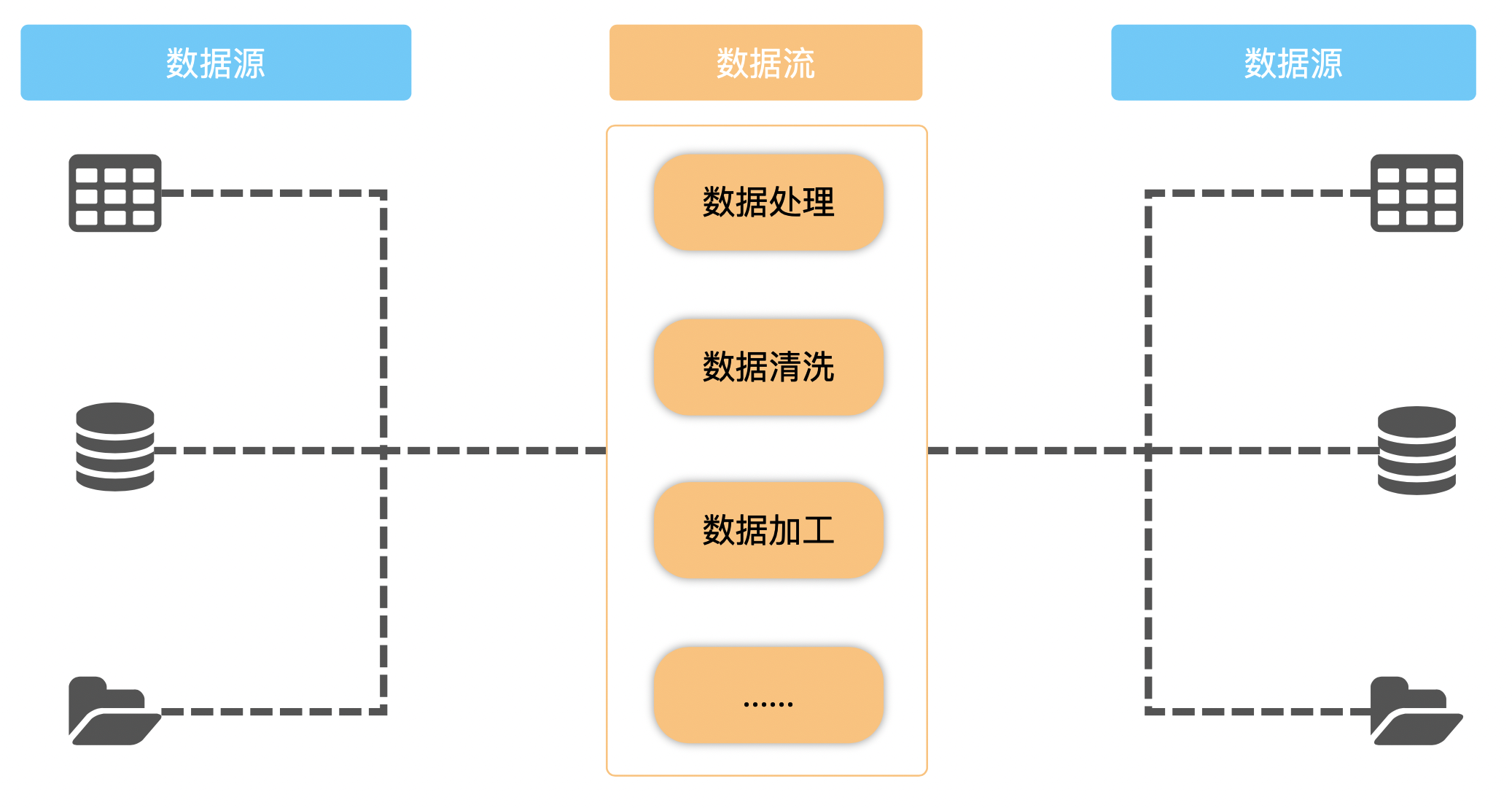
2. 概念释义
2.1 数据源
数据源是提供或接收数据的空间,数据流在数据源中执行数据存取动作。 从描述上看,数据源很像一个存放数据的仓库,其实事实也是如此,大部分的数据源都是数据库系统中的某一个表。但是,也有例外,可以把这个”仓库”抽象一下,只要能提供数据或者能够接受数据就行,他可以是一个返回数据的接口,也可以是某个服务器中的某一个数据文件,这些都可以叫做”仓库”,只是听起来怪怪的,所以改名为”数据源”。 也可以和物流类比,一个仓库可以是一个”数据源”,因为里面存放了货品(数据);一个人也可以是”数据源”,因为他手里可能就有要寄出去的东西(数据);一个店铺也可以是一个”数据源”,因为店里有客人点的外卖(数据)。 如果我们要把货物从一个仓库送到另一个仓库,我们需要一些实际的信息:
-
首先,我们需要知道这两个仓库的地址,经纬度是多少,或者说哪个省哪个市哪条街,这样我们才能知道去哪里取,送到哪里去;
-
然后我们需要有仓库的钥匙,通过要是才能打开库房,取出需要寄送的货物。
这两个东西,在数据库中也有参照:
我们把仓库地址叫做主机号和端口号,主机号和端口号加起来就是一个标准的网络地址;
我们把钥匙叫做用户名与密码,通过用户名和密码才能进入对应的数据库系统。
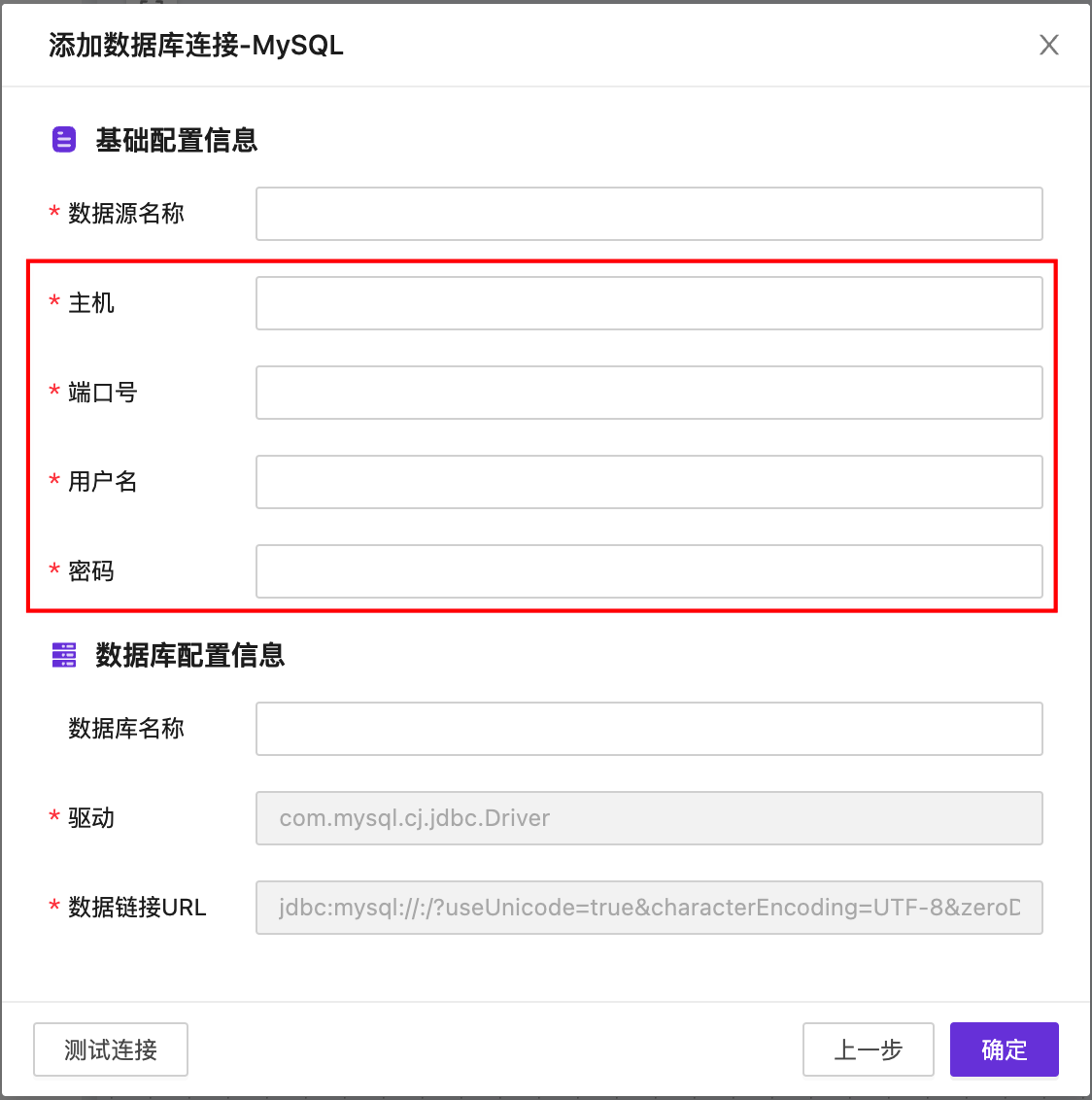 只不过这个”仓库”比较大,可能还需要告诉物流(数据流),你要取的货品(数据)在哪个房间(数据库名称)。
只不过这个”仓库”比较大,可能还需要告诉物流(数据流),你要取的货品(数据)在哪个房间(数据库名称)。
2.1.1 数据库连接
数据库连接是数据源的主要类型之一,主要用于定义一个数据库系统的连接信息,以便数据流通过该连接信息获取相关的数据。
每一个独立的数据库连接信息被称之为一个数据库连接,用户可以自定义该连接作为数据源的名称。
一般来说,通过主机号、端口号、用户名、密码以及相关的数据库名即可完成连接。
数据库连接还分为共享数据库连接和独立数据库连接。
共享数据库连接指的是在应用层面可共享给多个数据流使用的数据库连接信息。在数据流的编辑页面中,用户可以直接看到已经共享给当前数据流的所有共享数据库连接。
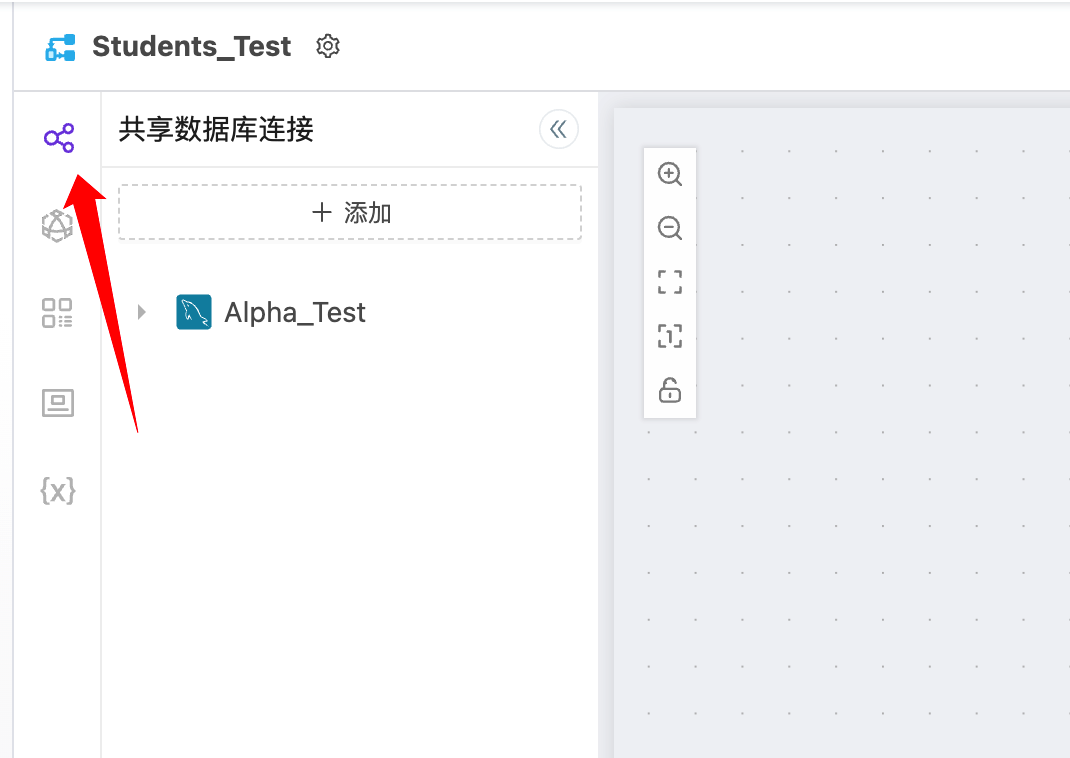 独立数据库连接指的是仅有当前数据流可使用的数据库连接信息,不可共享给其他的数据流。
独立数据库连接指的是仅有当前数据流可使用的数据库连接信息,不可共享给其他的数据流。
2.2 数据流
数据流是连接着数据源,对数据进行运输和加工的数据管道。 数据流既不能凭空产生数据,本身也不存储数据。他是通过连接数据源,从数据源中取得数据,将数据放入其流管道中,然后流向另一个数据源的数据通道。 类比物流,派遣去仓库(数据源)中取货(数据)的取货员,将货品(数据)打包并转送的站点,把货品(数据)送到指定地点(数据源)的送货员等等,在数据流中,我们统一称之为:节点。 与之相关的概念还有一个,就是控件。控件是”取货员”这个岗位,节点是担任取货员这个岗位的员工,可以叫张三,也可以叫李四。这种关系也被这样描述,控件是具有数据处理能力的一个模板,节点是这个模板的一个实例。
2.3 流程相关
数据流由一个个的流程节点连接而成,流程节点一般分为三类:读取数据的节点、写入数据的节点、处理数据的节点。 不同的节点有不同的数据能力,各个节点连接在一起,用彼此之间的位置关系来表示执行顺序,就形成了一个完整的数据流。
2.3.1 前序节点
前序节点指的是基于连接到当前节点的连接线可向前追溯到的节点。
下图是一个带分支的数据流截图:
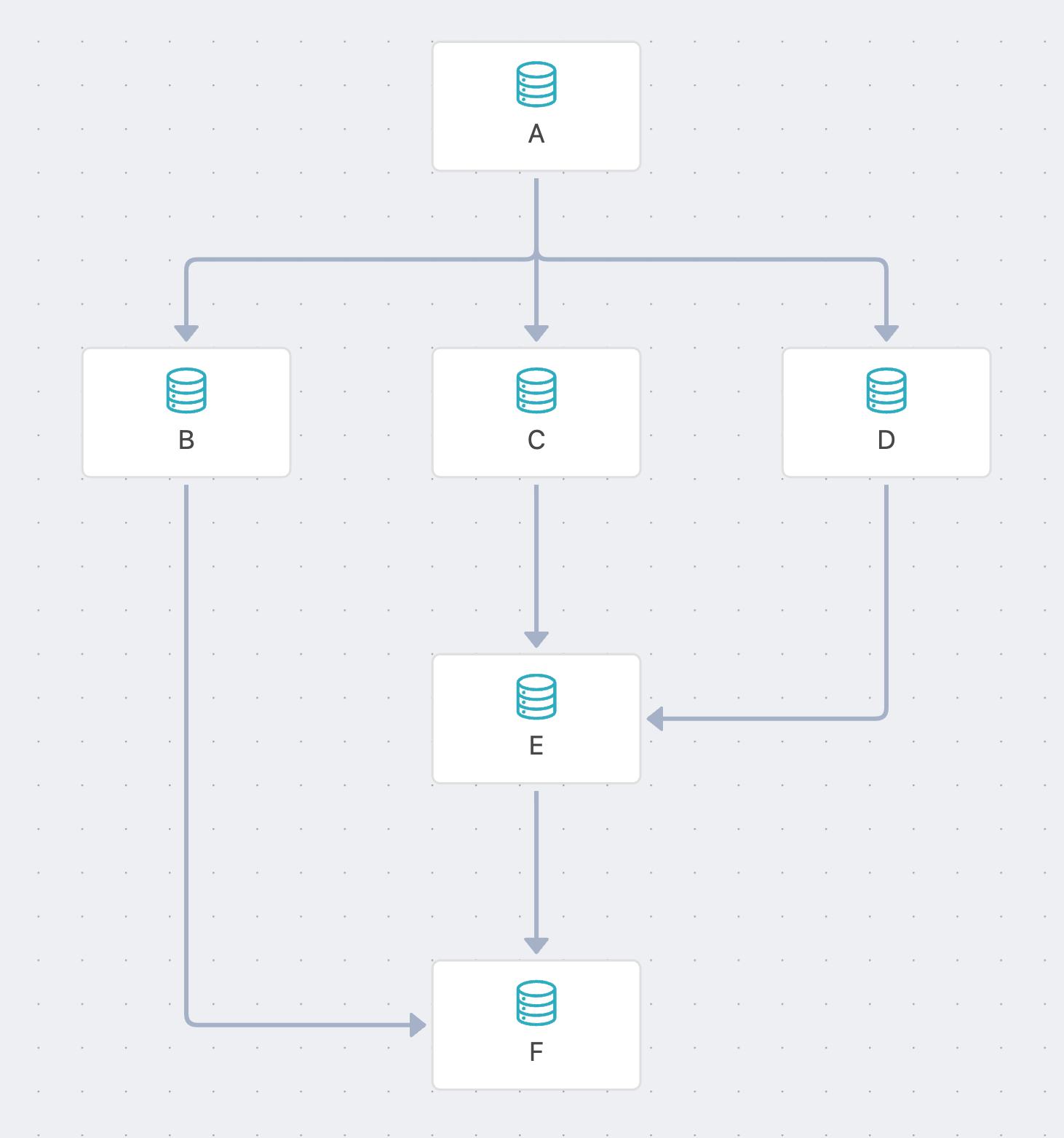 其中,以节点【E】为例,有两根连接线连接到【E】节点。
因此,可基于这两根连接线追溯到【C】和【D】两个节点,这两个节点均为E节点的前序节点。
再基于【C】和【D】的连接线可追溯到【A】节点,因此,【A】节点也是E节点的前序节点。
所以,【E】节点有3个前序节点,分别是【C】、【D】、【A】。
【B】节点是【A】节点的另一个分支,但无法从连接到【E】节点的连接线向前追溯到,所以,【B】节点不是【E】节点的前序节点。
同理可推得,【A】、【B】、【C】、【D】、【E】均为节点【F】的前序节点。
其中,以节点【E】为例,有两根连接线连接到【E】节点。
因此,可基于这两根连接线追溯到【C】和【D】两个节点,这两个节点均为E节点的前序节点。
再基于【C】和【D】的连接线可追溯到【A】节点,因此,【A】节点也是E节点的前序节点。
所以,【E】节点有3个前序节点,分别是【C】、【D】、【A】。
【B】节点是【A】节点的另一个分支,但无法从连接到【E】节点的连接线向前追溯到,所以,【B】节点不是【E】节点的前序节点。
同理可推得,【A】、【B】、【C】、【D】、【E】均为节点【F】的前序节点。
2.3.2 批次数据
数据流开始运行以后,会从每一个分支的第一个节点开始同时执行。
 每一个节点都会产生数据,可能是后续节点会用到的业务数据,也可能只是一个通知后续节点开始执行的请求数据,也有的节点会对数据进行拆分,分成多个批次放到流管道内。
就和物流一样,有的货品(数据)只是一封信,伸手就能拿到,有的货品(数据)则需要分成好几个箱子,分批运送。
每个节点都会产生至少一波数据,我们把这一波数据,称之为一个批次,多个节点的很多波数据,就是多个批次的数据。
类似上图,最左侧的【读取数据】节点和下方的【读取数据】节点都会产生至少一个批次的数据,因此【处理数据】节点就会收到至少2个批次的数据。
每一个节点都会产生数据,可能是后续节点会用到的业务数据,也可能只是一个通知后续节点开始执行的请求数据,也有的节点会对数据进行拆分,分成多个批次放到流管道内。
就和物流一样,有的货品(数据)只是一封信,伸手就能拿到,有的货品(数据)则需要分成好几个箱子,分批运送。
每个节点都会产生至少一波数据,我们把这一波数据,称之为一个批次,多个节点的很多波数据,就是多个批次的数据。
类似上图,最左侧的【读取数据】节点和下方的【读取数据】节点都会产生至少一个批次的数据,因此【处理数据】节点就会收到至少2个批次的数据。
2.3.3 数据格式
每个节点会产生n个批次的数据,并将这些数据放入流管道内。
与包裹一样,不同的物品有不同的包装方式,海鲜要冷藏,罐头要密封,易碎物品要垫海绵等等,数据也有不同的格式。
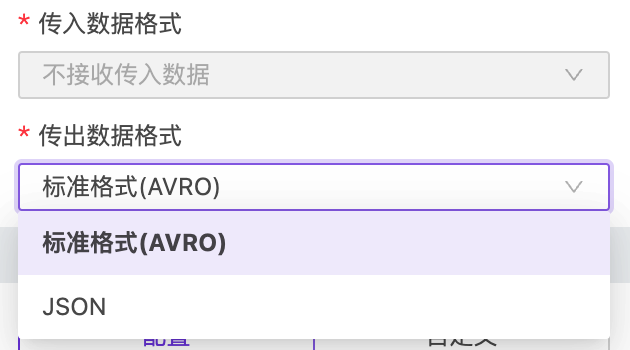
数据流的标准格式是AVRO,同时也支持JSON格式的数据在流内传输,不同的数据格式也可以通过不同的节点进行格式转换。
2.3.4 节点执行
除了每个分支的第一个节点以外,其他节点均在收到来自其他节点的批次数据时执行。
如果某一个节点收到了2个批次的数据,那这个节点就会执行两次。每次执行后,这个节点也会向其后续的其他节点传递一个批次的数据,同理,如果这个节点执行了n次,那这个节点也会产生n个批次的数据传递给后面的节点。
就好比双十一买了很多商品,这些商品可能也是分多个包裹运送的,每一个包裹都会被站点单独处理,10个包裹就是10个物流订单,哪怕是一模一样的路径,同样的站点,不会说这些包裹都是同一个用户的,那站点就等他的包裹全部到齐以后再打包往后送。
不过——数据比实际的商品要灵活,凡事总有例外。
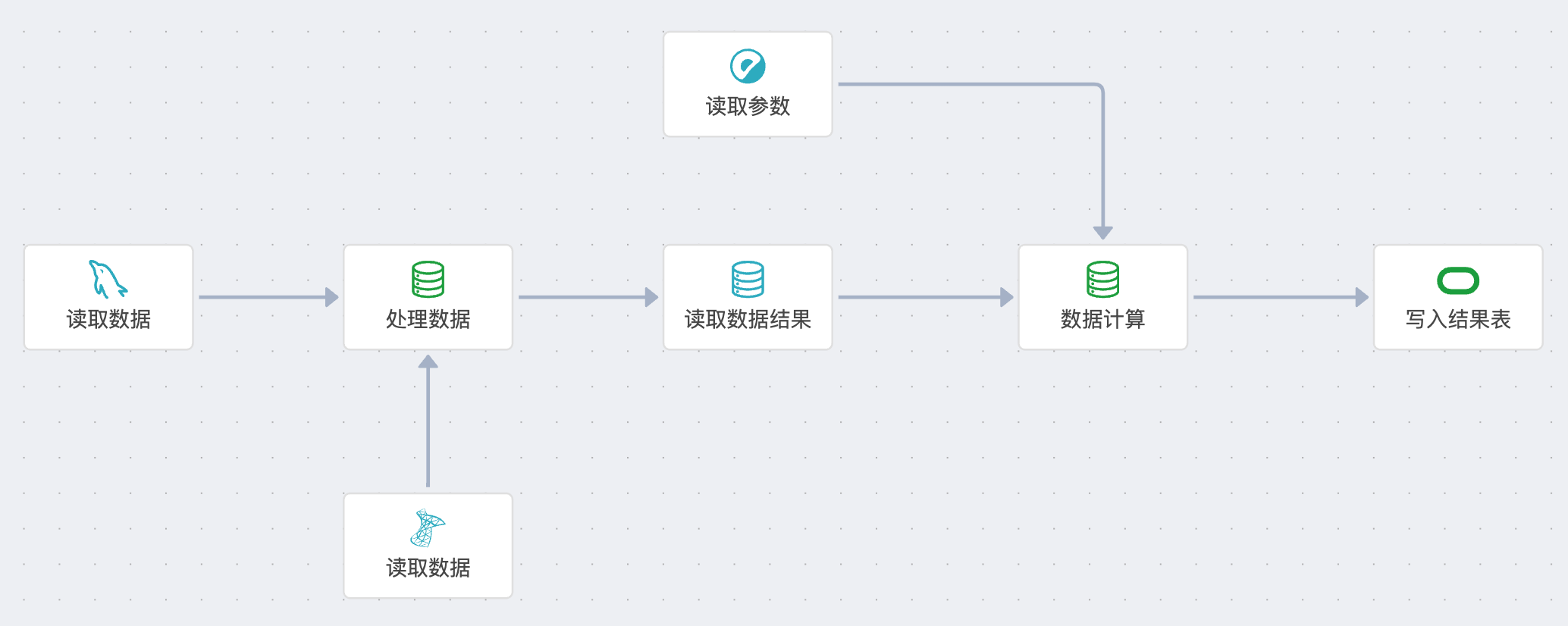
 如图所示,【数据计算】节点前面连接了【读取数据结果】和【读取参数】这两个节点,但是【读取数据结果】需要等待他前面的节点执行完了之后,才可以执行,而【读取参数】节点则是一开始就执行了。
按照上面的逻辑,【读取参数】节点执行完之后,【数据计算】节点就要开始执行了,如果此时【读取数据结果】还没有把需要计算的数据传过来,就会发生数据错误。
因此,节点执行还需要一些特殊的配置与条件。
如图所示,【数据计算】节点前面连接了【读取数据结果】和【读取参数】这两个节点,但是【读取数据结果】需要等待他前面的节点执行完了之后,才可以执行,而【读取参数】节点则是一开始就执行了。
按照上面的逻辑,【读取参数】节点执行完之后,【数据计算】节点就要开始执行了,如果此时【读取数据结果】还没有把需要计算的数据传过来,就会发生数据错误。
因此,节点执行还需要一些特殊的配置与条件。
2.3.4.1 等待执行
每个节点都可以配置一个执行逻辑——是否等待前序节点完成。 如果用户碰到了上图中【数据计算】节点的场景,就可以把【数据计算】的[等待前序节点完成]配置项打开,这样的话,哪怕【数据计算】收到了来自【读取参数】的批次数据,他依旧不会执行,因为他会等待他的所有前序节点执行完成后,再开始执行。 这样的执行逻辑就可以保证各节点在执行时的正确性了。
回到顶部
咨询热线
400-821-9199
